Сервіс по збору семантичного ядра: як працює сервіс по збору семантичного ядра
 Щоб сайт був видний в пошукових системах, а ще краще, щоб він займав лідируючі позиції у видачі, першим справу потрібно скласти семантичне ядро — набір слів і словосполучень, яким релевантний сайт.
Щоб сайт був видний в пошукових системах, а ще краще, щоб він займав лідируючі позиції у видачі, першим справу потрібно скласти семантичне ядро — набір слів і словосполучень, яким релевантний сайт.
Команда SEO-фахівців Inweb розробила і представила ще один інструмент в рамках проекту « Inweb Tools » — сервіс, який допоможе SEOшніку отримати семантику на основі аналізу посадкових сторінок конкурентів. Розповідаємо.
Зміст статті
Для чого потрібен сервіс зі збору семантики? </ h2>
Сервіс аналізує посадкові сторінки конкурентів, які знаходяться в ТОПі видачі, і на його підставі складає семантичне ядро. При цьому всі необхідні дані інструмент збирає з Serpstat .
Що таке семантичне ядро? </ h2>
Існує безліч визначень поняття «семантичне ядро». Ми прочитали більшість з них, об’єднали головне, виділили особливості і ось що вийшло.
Семантичне ядро – загальний список пошукових запитів, ключових слів, різних форм словосполучень, завдяки яким визначається розуміння виду діяльності та перелік послуг сайту.
Завдяки цим словам зі списку сайт можна і потрібно просувати. Семантика, як правило, враховує бажання, інтереси користувачів і разом з цим відповідає цілям компанії.
Для чого потрібно збирати семантичне ядро? </ h2>
Збір семантичного ядра дає розуміння бізнесу, яка структура попиту і що люди шукають в принципі.
Очевидно, що продаючи електронну техніку, ви не будете « претендувати » на користувача, який шукає в інтернеті корм для домашніх вихованців.
Ось кілька застосувань семантичного ядра:
- Необхідність у створенні нових сторінок сайту. Семантика допомагає зрозуміти, що саме і як часто шукають користувачі. Можна зробити аналіз пошукової видачі, вивчити конкурентів і відповісти на питання, чи потрібно створювати нові сторінки або існуючих на сайті достатньо. У разі, якщо сторінки сайту втратили актуальність і ви прийняли рішення про створення нових, пам’ятайте: треба правильно прописати редіректи — перенаправлення користувача з одного URL на інший. Для цього рекомендуємо використовувати сервіс « Відстань Левенштейна » . </ div> </ li>
- Складання метатегів. Ядро допомагає зрозуміти, за допомогою яких слів і конструкцій користувач шукає той чи інший товар, послугу, і що дійсно його цікавить. Отримані дані потрібно використовувати для створення відповідної назви та опису сторінки. Якщо все виконати правильно, сторінка стане релевантною, що добре позначиться на видачу сайту в пошуковій системі.
- Контент на посадкових сторінках. Крім коректного, з точки зору оптимізації, опису сторінки, важливу роль відіграє наявність якісного тексту на сайті. Правильно написаний текст, з урахуванням всіх ключових слів і інших нюансів, допоможе зробити сторінки більш доречними для пошукових систем і привабливими для користувачів. Складайте технічне завдання для копірайтера в один клік за допомогою сервісу « Завдання для текстів » . Інструмент працює на основі аналізу сайту конкурентів. </ div> </ li>
- Статті на сайт. Постійне ведення блогу — важливий компонент в просуванні не тільки свого сайту, але і всього бізнесу. Інформаційні та / або комерційні статті, розміщені в окремому розділі, можуть допомогти в залученні потенційних клієнтів. </ li>
Написання статей заради написання — ні до чого не приведе. Намагайтеся вибирати вузькоспрямовані теми, адже конкуренти можуть їх не зачіпати і ваш сайт буде потрапляти в ТОП видачі за цими пошуковими запитами.
Як працює інструмент для збору семантики? </ h2>
Сервіс містить в собі два методи збору семантичного ядра:
- за маркерними фразам; </ li>
- по URL-адресами конкурентів. </ Li>
Працюючи з маркерними фразами, інструмент отримує ТОП-10 по кожній фразі, бере URL-адреси з цього ТОПу і отримує їх список ключових фраз. Спираючись на вибрану кількість перетинів, видає підсумковий список загальних запитів за кожним маркерним словом.
У випадку з адресами конкурента, сервіс отримує список ключових фраз, за якими ранжуються сторінки, і далі працює аналогічно: виходячи з обраної кількості перетинів видає підсумковий список загальних запитів.
Збір даних за першим методом ґрунтується на конкурентів з пошукової видачі за високочастотними запитами, збирає фрази, за якими вони ранжуються в пошуковій видачі.
Маркерні запити — запити, які прямо відповідають просуває сторінці. Наприклад, для сторінки-категорії мобільних телефонів таким запитом буде & laquo; купити смартфон ».
Такий метод збору дає більш загальний і широкий набір ключових фраз, в порівнянні з другим методом. Найкраще підходить для швидкого збору семантичного ядра за декількома маркерним запитам в ніші, для якої існує велика кількість семантики. Наприклад, якщо вам необхідно зібрати семантику на сторінки інтернет-магазину з продажу електронної техніки.
Спосіб 1. Для збору семантики, використовуючи метод маркерних запитів, потрібно:
- Вказати пошукову сторінку і регіон:
 </ li>
</ li> - Вказати токен API Serpstat:

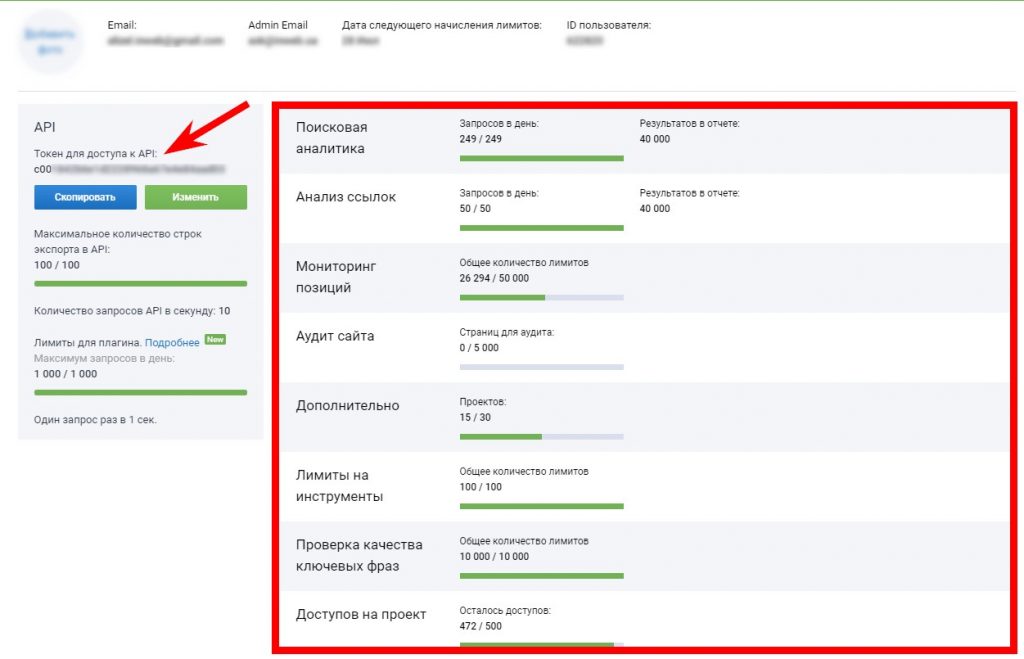
- Переконатися в тому, що лімітів досить. Для перегляду токена і кількості лімітів зайдіть у свій профіль в Serpstat:
 </ li>
</ li> - Ввести маркерні ключові слова. Нижче наведено приклад для магазину з продажу електронної техніки:
 </ li>
</ li> - Через кому можна ввести стоп-слова (фрази, які містять ці слова, не будуть включені в підсумковий список):
 </ li>
</ li> - Після всіх виконаних дій натискайте « Отримати семантичне ядро »:
 </ li>
</ li>
На екрані з’явиться таблиця ключових фраз з їх частотністю. Для зручності ми передбачили можливість вивантаження даних в форматі .CSV.
Спосіб 2. За URL-адресами. Щоб зібрати семантичне ядро, потрібно:
- Вказати пошукову сторінку і регіон:</ li>
- Вказати токен API Serpstat:</ li>
- Переконатися в тому, що лімітів досить. Для перегляду токена і кількості лімітів зайдіть в свій профіль в Serpstat:</ li>
- Ввести для аналізу url-адреси конкурентів з пошукової видачі:
 </ li>
</ li> - Визначити кількість перетинів — кількість сайтів з такими ж ключами в семантиці. Ми рекомендуємо обирати 3 перетину для 5 сторінок конкурентів:
 </ li>
</ li> - Ввести стоп-слова, використавши кому:</ li>
- Натиснути кнопку « Отримати семантичне ядро »:</ li>
</ ol>Ви отримуєте таблицю ключових фраз з їх частотністю. Для зручності таблицю з результатами можна вивантажити в форматі .CSV.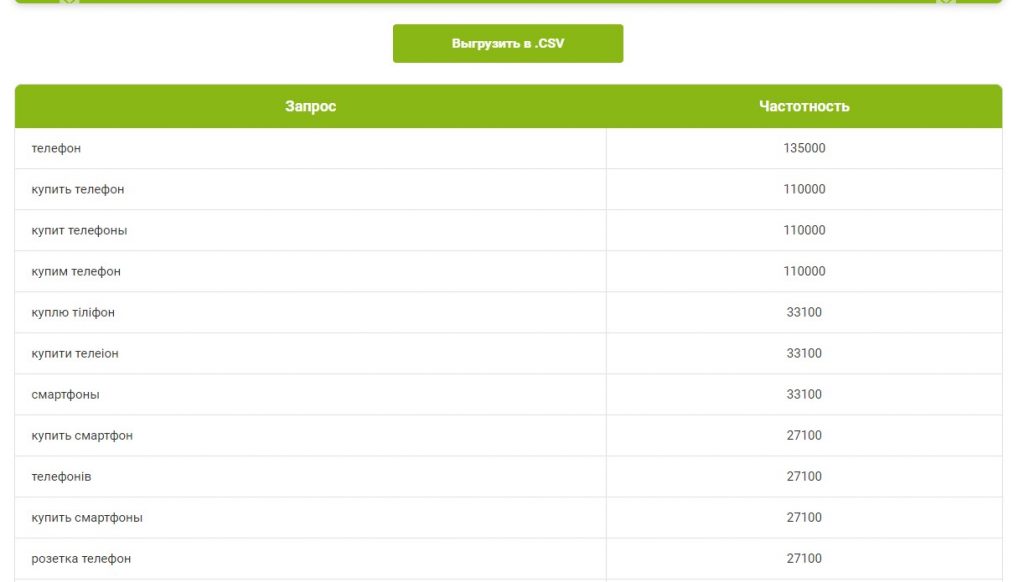
Помилки при роботі з семантичним ядром </ h2>
Як і в будь-якій справі, при роботі з семантичним ядром можна зіткнутися з деякими помилками.
Помилка 1: комерційні та інформаційні запити ведуть на одну сторінку </ strong>. Так ви ніколи не будете в ТОПі за запитом не того виду, оскільки у користувача інша суть питання і видача вже зайнята сторінками з найкращою відповіддю відповідного виду.
Як виправити: для таких запитів повинні бути зроблені окремі посадкові сторінки. Отже, запити « купити samsung galaxy s21 » і « samsung galaxy s21 розпакування » повинні вести на абсолютно різні сторінки.
Помилка 2: одна сторінка для регіональних представництв. Якщо у вас є представництва в різних регіонах, для просування в інших містах потрібно створювати окремі сторінки. Різні геозалежні запити показують різні результати, тому для кожного міста потрібна своя сторінка і відповідна інформація.
Як виправити: для кожного регіонального представництва потрібно створити окрему сторінку. Якщо сторінка відповідає магазину в Києві, то ні в якому разі не можна залишати для неї запити за типом « купити холодильник Харків » і навпаки. При такому розкладі ви не будете в ТОПі видачі.
Помилка 3. для всіх запитів – одна відповідь. До вас можуть потрапляти комерційні та інформаційні запити.
Як виправити: необхідно зробити перевірку — введіть ключову фразу в пошуковий рядок і поспостерігайте за результатом. Якщо більшість сторінок комерційні, значить користувачам необхідна комерційна відповідь, і навпаки: якщо 8 з 10 запитів інформаційні — варто підігнати інформацію під цей тип.
Пам’ятайте про потреби користувача, адже запит може бути не повністю комерційним або інформаційним, а на 70% або 80%.
Помилка 4: не відповідають мовній версії запиту. Не залишайте запити, які не відповідають мовній версії сторінки.
Як виправити: для просування на інших мовах доведеться створити окремі лендінги. В іншому випадку ваш сайт не зможе бути в ТОПі видачі.
Помилка 5: нехтування створенням нових посадкових сторінок. Визначення в потрібності нових посадкових – одна з цілей створення семантичного ядра. Якщо існує безліч запитів, відмінних від вихідного, є сенс задуматися про створення посадкової сторінки.
Як виправити: щоб перевірити необхідність створення окремої посадкової сторінки, введіть запит подібного виду в видачу і перевірте її. Якщо на верхніх рядках з’являються сторінки конкурентів з такими сторінками – робіть окрему посадкову сторінку на своєму сайті. Якщо з’являються тільки картки товарів – окремо створювати посадкову не треба.
З яким обмеженнями можна зіткнутися </ h2>
З огляду на нюанси сервісу зі збору семантичного ядра, ви зможете убезпечити себе від помилок. По-перше, переконайтеся, що токен для доступу до API Serpstat робочий і містить достатню кількість лімітів. По-друге, запам’ятайте, що запит для пошуку знаходиться в базі Serpstat. І, по-третє, – чим більше вкажете перетинів, тим релевантні і чистіше буде список пошукових запитів.
Знаючи всі нюанси й використавши наш сервіс зі збору семантичного ядра, ви зможете обійти конкурентів і отримати максимум конверсії.
![]()