Дублі сторінок: що це, як і де шукати, чим боротися

Зміст
Дублі сторінок – це погано. Чому? З ними сайт не може оцінюватися пошуковими системами і ранжуватися на високі позиції. Ми розпочали з постановки проблеми, яка має рішення. Визначимося з термінологією та перейдемо до того, як уникнути повторення сторінок, виправити помилки, і, таким чином, не проґавити хороші позиції сайту.
Що таке дублікати?
Дублі — однакові за змістом сторінки сайту, які доступні за різними URL-адресами. Тобто адреси сторінки не мають подібності, а їхнє наповнення повністю або практично повністю збігається. Навіщо це веде з погляду пошукових систем?
- Вони “не розуміють”, яку зі сторінок треба видавати відвідувачам на запит, і яку слід ранжувати.
- Основна сторінка може бути проігнорована пошуковими системами, а пріоритетніше виявиться дублікат.
- Пошукова система сприймає сайт з великою кількістю дублікатів як низькоякісний і не оцінює його високо.
- Дублі знижують відсоток якісних сторінок, який враховується пошуковими системами.
Якщо з 150 000 сторінок приводять відвідувачів лише 250, це знак для пошукових систем, що якість сайту низька. Тому рекомендуємо: якщо сторінки почали дублюватися, це треба виправляти одразу. Про те, як, читайте далі.
Причини виникнення дубльованих сторінок
Розгляньмо всі можливі ситуації, коли виникають дублі на сайті.
- Особливості CMS, системи керування контентом. Буває так, що один матеріал на сайті знаходиться у кількох рубриках. Їх URL включені в адресу сайту самого матеріалу. Тоді дублі виглядають так:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/
- Технічні розділи сайту. Можливо, що одна з функцій ресурсу – пошук по сайту, блок фільтрів, форм реєстрації – створює параметричні адреси з однаковими даними по відношенню до сайту без параметрів на адресі сторінки. Може виглядати так:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y
- Неуважність адміністратора сайту. Випадковість, коли стаття існує у кількох розділах сайту через людську помилку.
- Технічні помилки. Коли посилання генеруються некоректно або неправильно налаштовані параметри системи управління інформацією. Помилки викликають дублювання сторінок. На прикладі Opencart, якщо посилання встановлено неправильно, то можемо отримати таке зображення:
site.ru/tools/tools/tools/…/…/…
Класифікація дублів
Повні дублі: звідки вони беруться?
Повні дублі — це сторінки, які мають однакове наповнення, і вони доступні за унікальними адресами, що відрізняються. URL у дублікатів завжди не збігатиметься.
Приклади повних дублів:
- Різниця тільки в слеші в кінці. Обидві сторінки точно не проіндексуються. Якщо вони вже потрапили в індексацію, потрібно виправляти.
http://site.net/catalog/product
http://site.net/catalog/product/
- HTTP та HTTPS-сторінки. Можуть бути дублі на протоколах із захистом та без. У такому разі сайту не світять хороші позиції у видачі.
https://site.net
http://site.net
- З “www” на початку і без “www”. У цій ситуації діяти треба якнайшвидше:
http://www.site.net
http://site.net
- Адреса сторінок з різними варіантами в кінці – index.php, index.html, index.htm, default.asp, default.aspx, home. Наприклад:
http://site.net/index.html
http://site.net/index.php
http://site.net/home
- URL-адреси, написані в різних регістрах.
http://site.net/example/
http://site.net/EXAMPLE/
http://site.net/Приклад/
- Порушено ієрархію URL. Картка товару може бути доступна за різними URL-адресами:
http://site.net/catalog/dir/tovar
http://site.net/catalog/tovar
http://site.net/tovar
http://site.net/dir/tovar
- Додаткові параметри та мітки в URL. Наприклад, із GET-параметрами:
http://site.net/index.php?example=10&product=25
Її дубль буде:
http://site.net/index.php?example=25&cat=10
- UTM-мітки. Приклад сторінки з UTM-міткою для збору аналітики:
http://www.site.net/?utm_source=adsite&utm_campaign=adcampaign&utm_term=adkeyword
- Установки Google Click Identifier. Також необхідний для відстеження даних про кампанію, канал та ключові слова в Google Analytics.
Наприклад, відвідувачі переходять за вашим оголошенням для сайту http://site.net, та адреса сторінки така: http://site.net/?gclid=123xyz.
- Мітка Openstat. Також потрібна для аналізу ефективності рекламних кампаній, трафіку сайту та поведінки відвідувачів. Виглядає так:
http://site.net/?_openstat=231645789
- Реферальне посилання. Має спеціальний ідентифікатор, яким фіксується, звідки прийшов новий відвідувач. Наприклад:
https://site.net/register/?refid=398992
http://site.net/index.php?cf=reg-newr&ref=Uncerttainty
- Перша сторінка пагінації каталогу товарів інтернет-магазину або дошки оголошень, блогу, часто відповідає сторінці категорії або спільного розділу pageall:
http://site.net/catalog
http://site.net/catalog/page1
- Неправильні налаштування помилки 404 (неіснуюча сторінка). Вони повинні віддавати код відповіді сервера 404, а не 200 або перенаправляти на актуальну сторінку. Наприклад:
http://site.net/seo-audit-465745-seo
http://site.net/3333-???
Часткові дублі: що вони є?
Часткові дублі — це коли частково контент дублюється на кількох сторінках, але вони не однакові. Можуть з’являтися через особливості конкретної CMS. Знайти такі дублі значно складніше за повні.
Такі з’являються через сторінки фільтрів, сортувань та пагінації. Наприклад, відвідувач використовує фільтр для пошуку товарів, адреса сторінки зовсім небагато змінюється. У відповідь на це пошукові системи індексують сторінку як окрему. Контент при цьому не змінюється, а SEO-складник дублюється.
http://mysite.com/catalog/category/ – стартова сторінка категорії товарів;
http://mysite.com/catalog/category/?page=2 — сторінка gf.
З блоками коментарів та описів майже та сама ситуація. Якщо користувач натискає на блок відгуків, це створює додатковий параметр в адресі сторінки, але вона, по суті, залишається такою самою. Контент при цьому не змінюється, а просто відкривається новий таб.
Сторінки друку та PDF для завантаження повністю повторюють контент сайту. Як це виглядає?
http://site.net/novosti/novost1
http://site.net/novosti/novost1/print
Контент сторінки повністю повторює SEO-складову сторінки сайту. Версія тут простіша, оскільки немає безлічі рядків коду, який потрібен для забезпечення роботи функціоналу. Виглядає порівняно це так:
http://mysite.com/main/hotel/al12188 — сторінка готелю
http://mysite.com/main/hotel/al12188/print — Ч/Б версія для друку
http://mysite.com/main/hotel/al12188/print?color=1 — Кольорова версія для друку.
Ще одна причина таких дублів – HTML-зліпки сторінок сайту, що створюються технологією AJAX. Щоб знайти їх, замініть в оригінальній URL-адресі “!#” на “?_escaped_fragment_=”. Найчастіше такі сторінки індексуються лише тоді, коли були неточності у впровадженні методу індексації AJAX-сторінок через перенаправлення робота на сторінку-зліпок. У такому випадку робот обробляє дві URL-адреси: основну та її html-версію.
Основна небезпека часткових дублів у тому, що вони не призводять до різких втрат у ранжируванні, а роблять це поступово та непомітно для власника сайту. Тобто знайти їхній вплив складніше і вони можуть систематично, протягом тривалого часу «отруювати життя» оптимізатору та його сайту.
Як знайти дублі на сайті?
Є кілька способів, щоб знайти дублі сторінок на вашому сайті.
Сервіси та програми
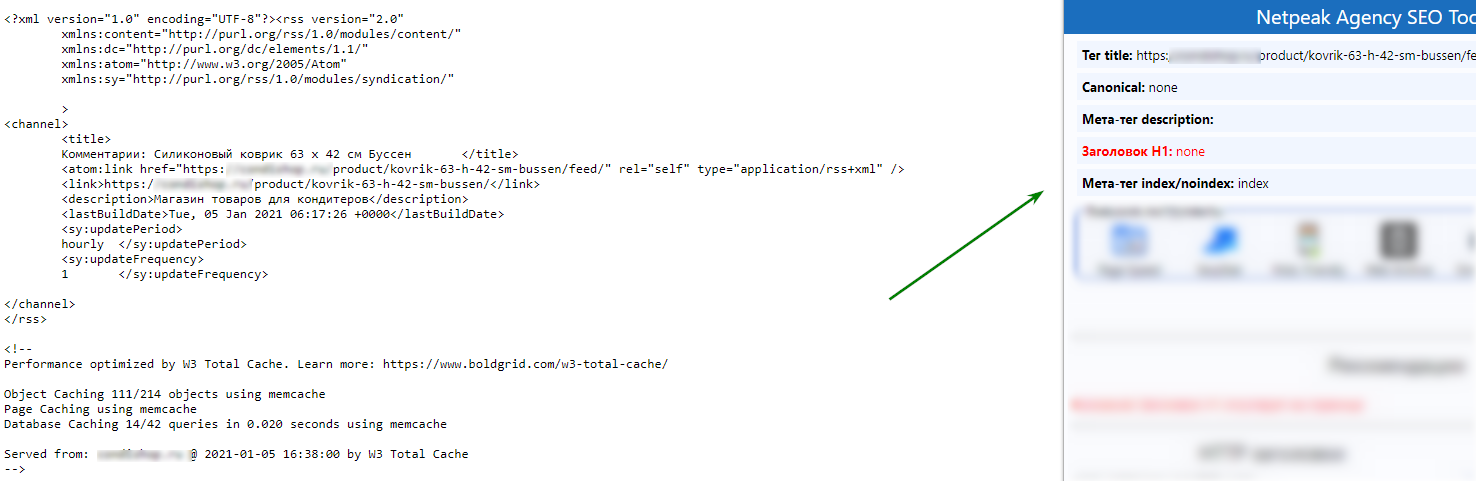
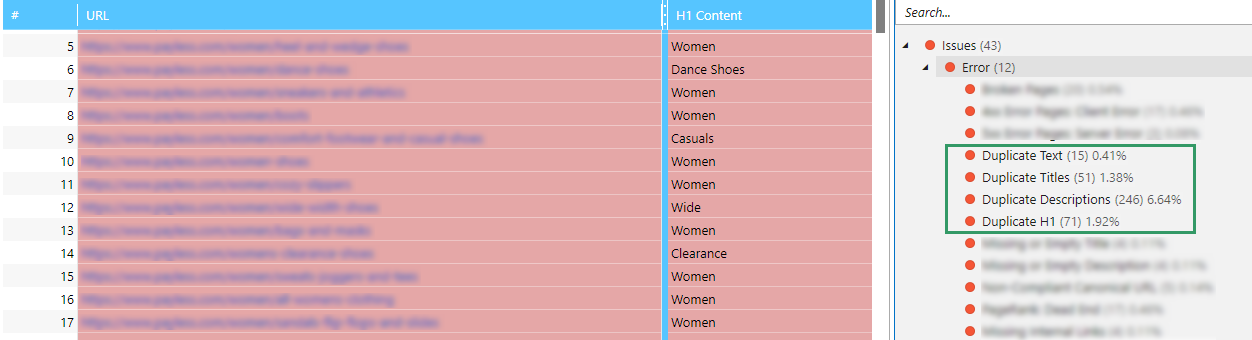
Screaming Frog Seo Spider та Netpeak Spider. Вони відмінно підходять для аудиту та виявлення дублів. Їхні роботи покажуть повний список URL-адрес. Потім його можна відсортувати за повторенням Title або Description. Тож ви знайдете можливі дублі.
Пошукові оператори та фрагменти тексту
Перший спосіб. Використовуйте пошуковий оператор “site:”. У Google введіть запит “site:examplesite.net”. Він покаже сторінки ресурсу загальної індексації. Так буде видно кількість сторінок у видачі.
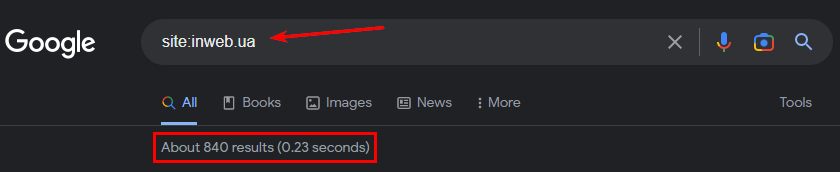
У видачі можна знайти дублі, «сміттєві» сторінки. Їх можна буде видалити з індексу, щоб позиції сайту не падали через них.
Другий спосіб. Використовуйте пошук за фразою з тексту зі сторінок сайту. Вибирайте такі, які можуть мати копії. Візьміть у лапки фразу з тексту, після нього ставте пробіл, додайте оператор «site:» та вводіть у пошуковий рядок. Важливо прописати ваш сайт, щоб знайти сторінки, де є такий текст. Наприклад:
«Фрагмент тексту зі сторінки сайту, який може мати дублі» site:examplesite.net
Якщо у видачі пошуку лише одна сторінка, то копій немає. Якщо ви бачите кілька, проаналізуйте їх та виявите причини. Можуть бути такі, які потрібно забрати максимально швидко.
За допомогою оператора intitle: аналізуємо вміст Title на сторінках, які є у видачі. Дублювання Title може означати дублювання сторінок. Для перевірки цієї теорії використовуйте пошуковий оператор «site:». Введіть такий запит:
site:examplesite.net intitle: повний або частковий текст тега Title
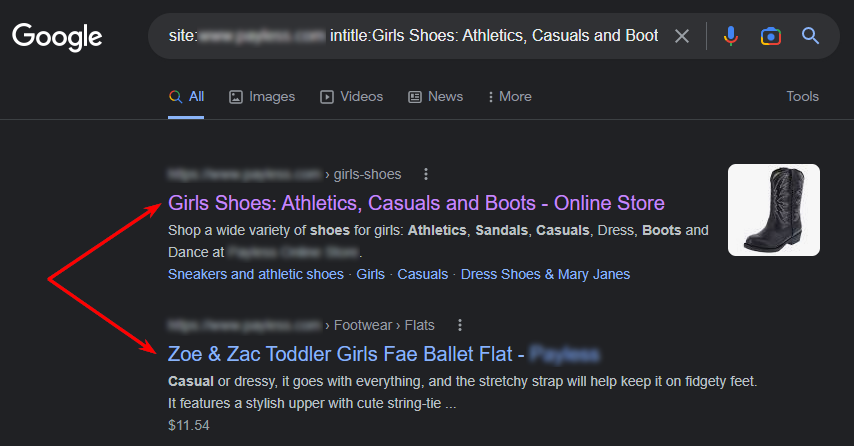
З операторами “site” та “inurl” можна визначити копії, які з’явилися на сторінках сортувань (sort) або фільтрів та пошуку (filter, search).
Для пошуку сторінок сортувань, напишіть у пошуковому рядку:
site:examplesite.net inurl:sort
Для пошуку сторінок фільтрів та пошуку:
site:examplesite.net inurl:filter, search
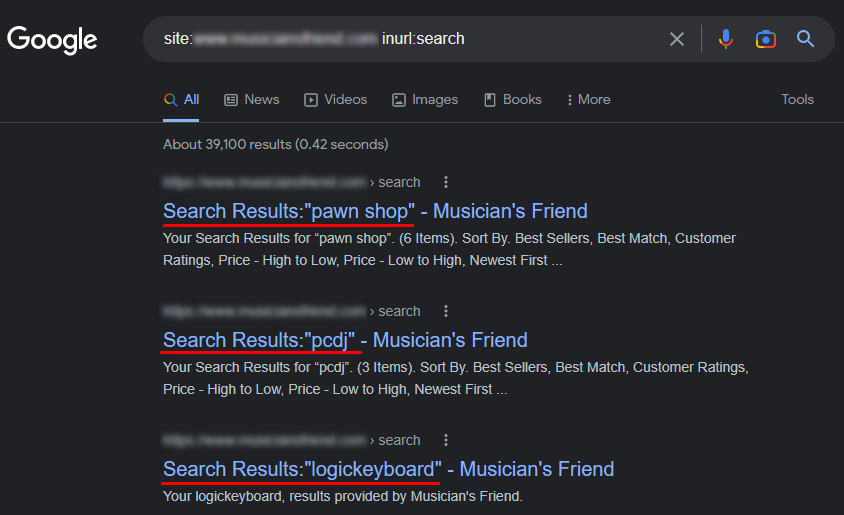
Панель Search Console Google
Пошукові системи покажуть копії сторінок і навіть підкажуть, як їх усунути.
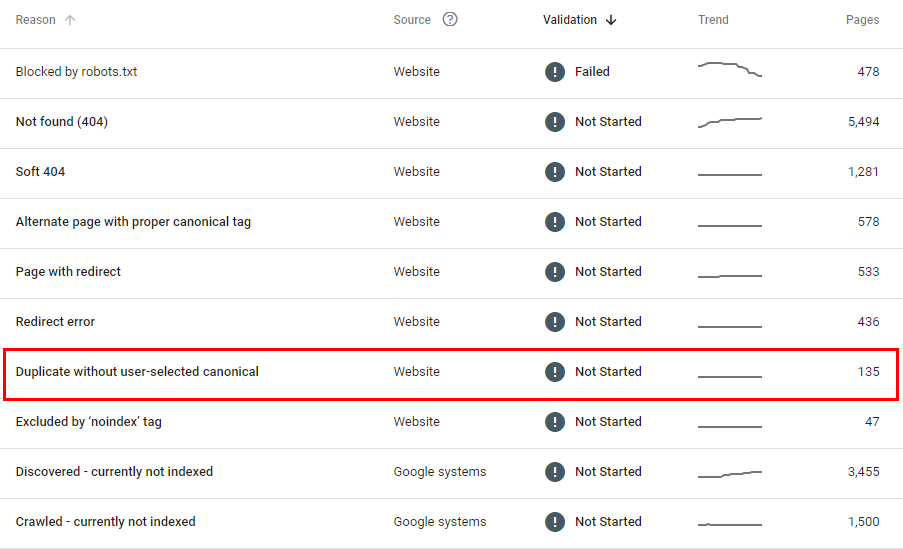
У Google Search Console у розділі “Покриття” дивимося в пункт зі сторінками, виключеними з індексування:
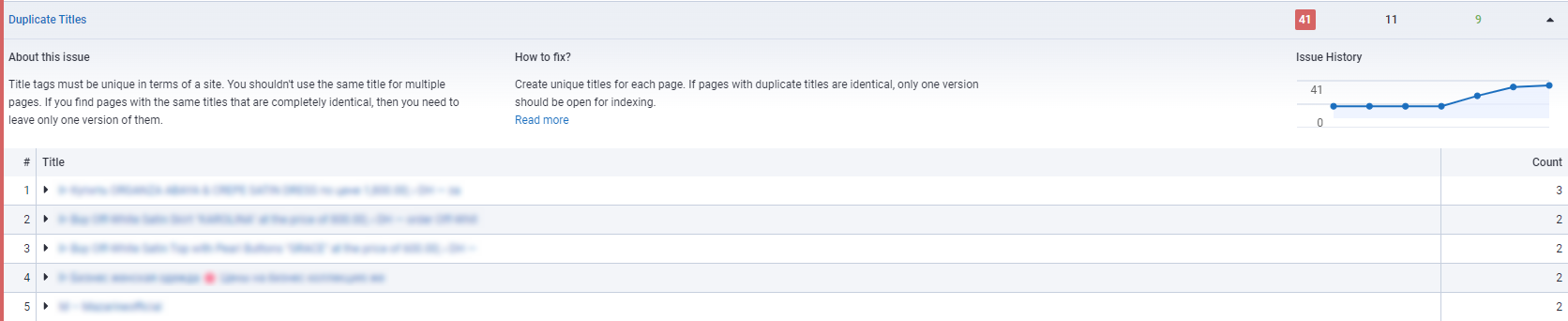
Serpstat
Тут вам потрібний інструмент «Аудит сайту» від Serpstat. Він покаже технічні помилки. Перейдіть до розділу “Метатеги” і знайдіть пункт “Дублірований Title” або “Дублюючий Description”.
До чого призводять дублі сторінок на сайті?
Пошукові системи з різних адрес сприймають такі сторінки як різні. Це веде до низки проблем ранжирування та супутніх. Яких саме?
- Погана індексація. Розмір сайту через копії зростає, а пошукові системи, індексуючи надмірний обсяг сторінок, неефективно витрачають краулінговий бюджет власника сайту. Важливі та дійсно корисні для користувачів сторінки можуть ігноруватись індексацією.
- Не та сторінка у видачі. Алгоритми пошукової системи можуть зробити висновок, що копія більш релевантна запиту, і у видачі буде не та сторінка, яку ви цілеспрямовано просували. Ще один сценарій – у видачі не буде ні оригіналу, ні копії.
- Втрата ваги сторінок, які ви просуваєте. Відвідувачі можуть надсилати посилання на копії, а не на оригінали. Як результат – природна маса посилань втрачається.
Що таке неінформативна сторінка?
Більше 50 факторів ранжирування відповідають лише за вміст сторінки. Також є кілька змішаних – таких, що відповідають за текст та анкори вхідних посилань та ін.
Сторінки сайту називають неінформативними, якщо вони не оптимізовані під потреби користувача. Вони ніколи не принесуть користь вашому ресурсу. Чи не залучать трафік, не згенерують ліди. Вони навіть можуть зробити гірше та знизити поведінкові чинники. Приклад:
Це також можуть бути сторінки результатів пошуку по сайту. Так буває, якщо фрагмент /search/ в URL не закритий метатегом noindex. Ще одна причина – сторінка відновлення пароля відкрита для індексації.
Як боротися з кожним типом дублів?
- Завжди використовуйте для закриття від індексації лише метатег Robots або HTTP-заголовок X-Robots-Tag. Цим методом можна користуватися, якщо дублі з’явилися через сортування, фільтри та пошуки всередині сайту. Так ми показуємо пошуковим роботам, які сторінки чи файли не потрібно сканувати.
Використовуйте директиву Disallow, яка забороняє пошуковим роботам заходити на непотрібні сторінки.
User-agent: *
Disallow: /page
Якщо сторінка вказана у robots.txt з директивою Disallow, вона все одно може опинитися у видачі. Так трапляється, якщо вона була проіндексована раніше/на неї є внутрішні чи зовнішні посилання.
- Налаштування 301-редиректів за допомогою файлу “.htaccess”. Таким чином, можна прибрати копії головної сторінки або посилання реферальних програм, і цей спосіб вважається основним у випадку з повними дублями. З 301 редиректом ви передаєте з дубля посилальну вагу. Працює в ситуаціях, коли URL у різних регістрах, порушена ієрархія URL, для визначення основного дзеркала сайту або ситуації зі слішами в URL.
301 редирект використовують, щоб перенаправити з таких сторінок:
http://site.net/catalog///product
http://site.net/catalog//////product
http://site.net/product
на сторінку http://site.net/catalog/product
- Налаштування атрибуту rel=”canonical”. Підійде до повних копій. Якщо сторінка хоч трохи відрізняється – сторінки не зможуть склеїтися. Допомагає, коли сторінку не можна видалити і її потрібно залишити відкритою для користувачів.
rel=”canonical” підходить для видалення копій, створених використанням фільтрів та сортувань, а також для адрес, сформованих із застосуванням з get-параметрів та utm-міток.
- Використовується для друку, якщо вміст є однаковим у різних мовних версіях та на різних доменах.
- Підтримується не всіма пошуковими системами, але Google його відмінно розпізнає.
- Це посилання вказує адресу сторінки, яка має бути проіндексована.
- Тег. З ним ви видаляєте копії, створені сторінками друку та версіями PDF.
Для створення канонічної в HTML-код поточної сторінки вставляємо rel=”canonical” між тегами…. Виглядає так:
http://site.net/index.php?example=10&product=25
http://site.net/example?filtr1=%5b%25D0%,filtr2=%5b%25D0%259F%
http://site.net/example/print
Канонічна у цьому випадку – сторінка:
http://site.net/example
У HTML коді це виглядатиме так:
<link rel=”canonical” href=”http://site.net/example” />
- Метатег <meta name=”robots” content=”noindex, nofollow> та <meta name=”robots” content=”noindex, follow>. Перший дає команду роботу не піддавати індексації документ і не переходити за посиланнями. Це пряма директива, яка не проігнорується пошуковими роботами. Другий дає команду роботу не індексувати документ, але при цьому переходити за посиланнями, які в ньому розміщені.
Розміщений метатег виглядає так:
<meta name=”robots” content=”noindex, nofollow” />
<meta name=”robots” content=”none” />
<meta name=”robots” content=”noindex, follow” />
Залишились запитання чи хочете уточнити, як боротися з конкретним видом дублікатів сторінок? Задавайте запитання у коментарях – відповім на все детально та підписуйтесь на інші корисні матеріали у нашому Телеграм-каналі .
