Дослідження: чи може людина відрізнити контент, створений штучним інтелектом
 Завдяки стрімкому розвитку технологій, штучний інтелект (ШІ) стає краще імітувати роботу людини. Від написання текстів до генерації зображень, інструменти на кшталт ChatGPT, Copy.ai, MidJourney та DALL-E продемонстрували здатність впливати на сприйняття контенту й генерувати фейки. Тому розрізнення між контентом створеним людиною та результатами машинного навчання стає все складнішим завданням.
Завдяки стрімкому розвитку технологій, штучний інтелект (ШІ) стає краще імітувати роботу людини. Від написання текстів до генерації зображень, інструменти на кшталт ChatGPT, Copy.ai, MidJourney та DALL-E продемонстрували здатність впливати на сприйняття контенту й генерувати фейки. Тому розрізнення між контентом створеним людиною та результатами машинного навчання стає все складнішим завданням.
Компанія Nexcess провела дослідження, яке дає зрозуміти, наскільки точно люди відрізняють ШІ-контент від створеного людиною. Ми вирішили перекласти та адаптувати це дослідження для читачів блогу Inweb.
Проблема контенту, створеного ШІ
Зростаюча популярність інструментів штучного інтелекту та їх розповсюдження для широкого кола осіб викликає занепокоєння. Через це відомі люди, такі як співзасновник Apple Стів Возняк, інвестор Воррен Баффет, генеральний директор Getty Images Крейг Пітерс і ще 33 708 людей підписали відкритого листа, який мав спонукати призупинити розробку всіх ШІ-моделей, потужніших за ChatGPT-4, на 6 місяців. За цей час планувалося створити системи моніторингу для розпізнавання ШІ-контенту та закласти фундамент законодавства, яке б надалі регулювало проблеми генеративного контенту.
Мова йде про наступні проблеми контенту, створеного штучним інтелектом:
- Маніпуляція та викривлення фактів.
- Порушення прав авторської та інтелектуальної власності.
- Можливість втрати робочих місць, через оптимізацію із застосуванням ШІ.
- Транслювання стереотипного та неетичного контенту, контенту, який може містити дискримінацію та мову ворожнечі.
- Розповсюдження неякісного контенту.
- Складність у розмежуванні контенту створеного людиною від того, що був створений ШІ.
До прикладу, технологія deepfake, яка використовує генеративні змагальні мережі (GANs), щоб створювати реалістичні відео з відомим людьми. Це може бути використано для створення фальшивих новин, дискредитації публічних осіб або маніпуляції громадською думкою.
Наступним прикладом слугує проблема штучного інтелекту створювати музику, тексти, картини та фото, які можуть випадково або навмисно відтворити існуючі твори, захищені авторським правом. Не так давно розробник Ліам Свейн використав ШІ та оригінальні тексти Джорджа Р. Р. Мартіна для того, щоб дописати книги з циклу «Гра престолів», порушивши права власності.
Наслідуючи контент людини, стиль написання текстів чи техніку малювання ШІ створює проблему з розмежуванням генеративного контенту та того, що створила людина. Тому дослідження Nexcess та його результати дають можливість зрозуміти глибину проблеми, важливість маркування контенту створеного ШІ та набуття людьми нових навичок, які допомагатимуть відрізнити ШІ-контент.
Деталі дослідження
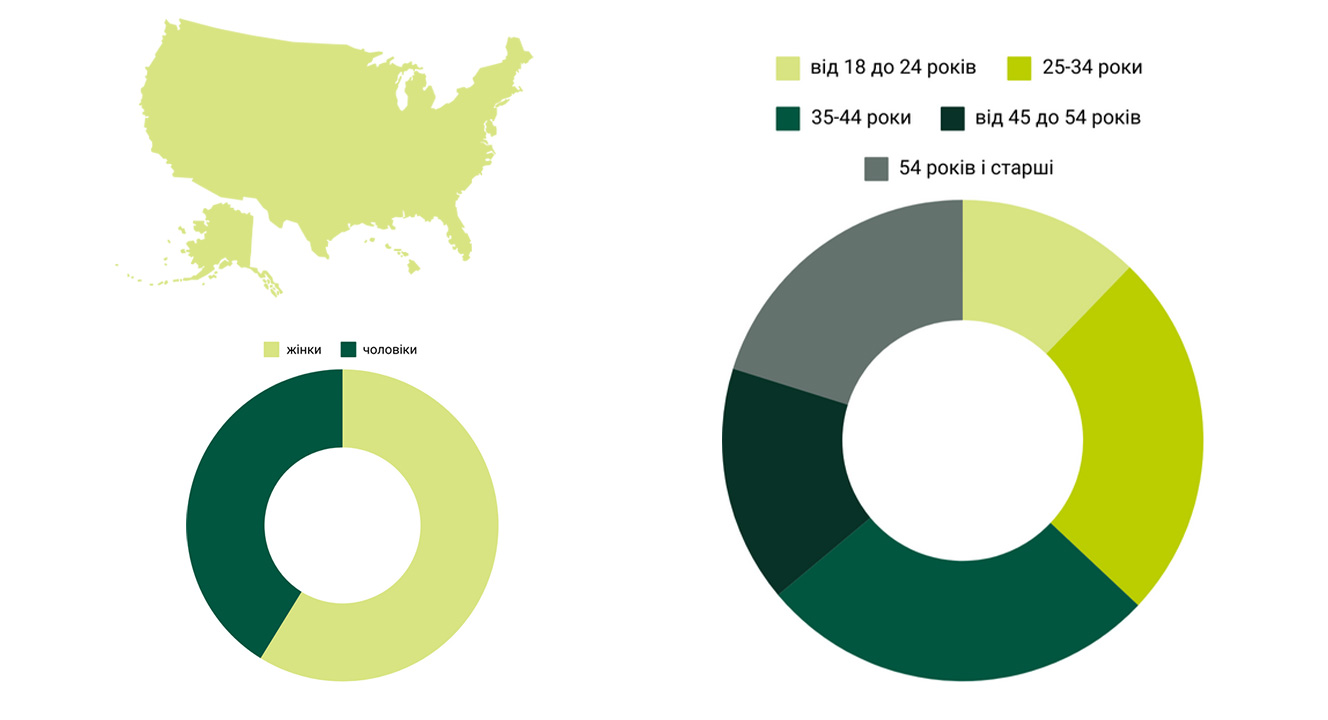
Компанія проводила опитування серед 1000 американських респондентів різних вікових груп. За ствердженням Nexcess, анкетування проводилося серед тих учасників, які помірно знайомі із ШІ.
- Країна, де проводилося дослідження: Америка.
- Кількість опитаних: 1000 респондентів із яких 412 чоловіки та 588 жінки.
- Вікові показники: 12.1% респондентів мали вік від 18 до 24 років, 24.6% віку 25-34 роки, 26.7% мали 35-44 роки, 15.8% склали люди віком від 45 до 54 років, 20% становили люди віком від 54 років і старші.
Дослідження проходило наступним чином: респондентам показували копії картинок та текстів, одне з яких створене людиною, а інше — штучним інтелектом. Щоб зробити дослідження обʼєктивним, експерти виключили з опитувальника зображення людей, оскільки ШІ має проблему з генерацією облич.
Результати дослідження
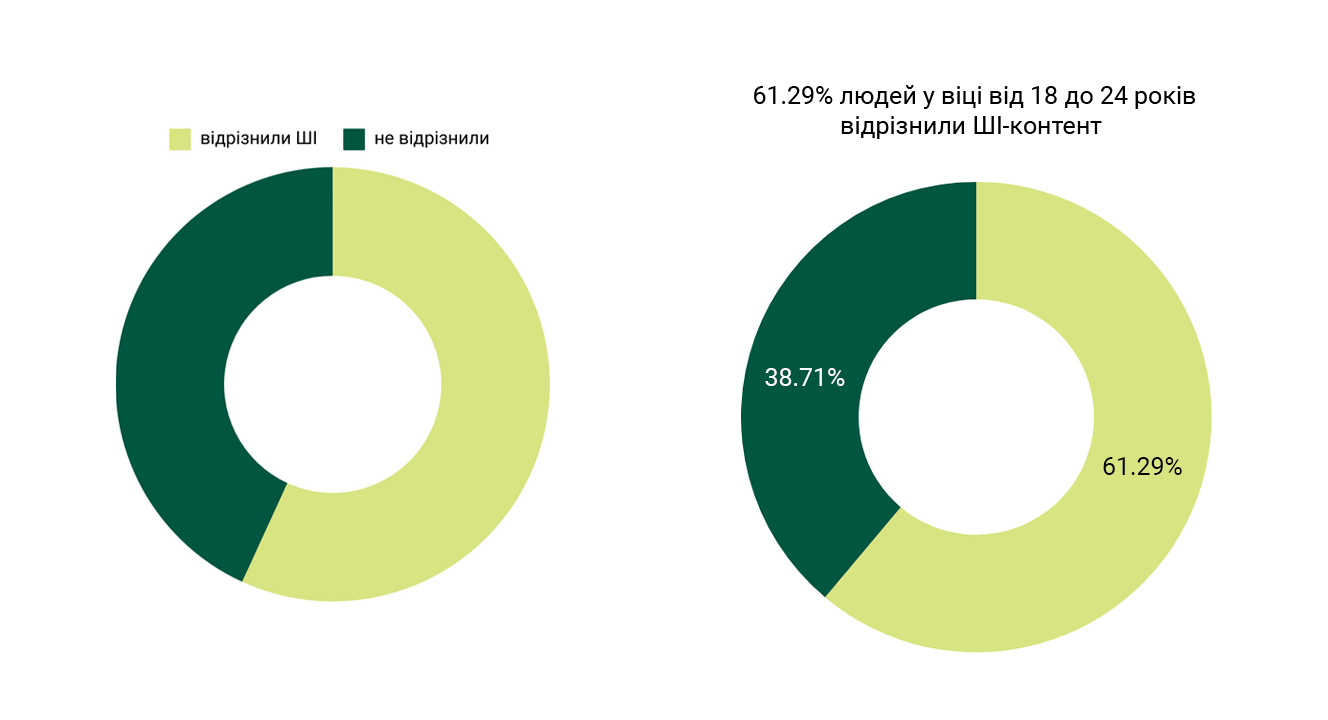
- Здатність розрізнення контенту: 54.64% респондентів змогли правильно відрізнити контент згенерований ШІ від створеного людиною.
- Вплив вікових факторів: у ході дослідження виявилося, що молодше покоління, зокрема учасники віком від 18 до 24 років, показало кращі результати, ідентифікуючи ШІ-контент із точністю до 61.29%.
- Текст чи зображення: текст, створений ШІ, учасники впізнавали легше, ніж зображення. Показники склали 57.3% проти 53.36% для згенерованого тексту та зображень відповідно.
В учасників опитування складність виникала з окремими зображеннями. Як-от ці зображення велосипеда. Більш ніж половина (54.6% опитаних) вирішили, що зображення помаранчевого велосипеда було згенероване ШІ, хоча його створила людина.

Також труднощі у розпізнаванні згенерованого контенту викликали зображення шампуню, яке сприйняли за згенероване 51% опитаних, тоді як воно було створене людиною. Такої ж помилки допустилися ще 53.4% респондентів із зображенням холодильника, виділивши його як згенероване.

Як люди різного віку відрізняють ШІ-контент
Цікава тенденція, яку виявило опитування, полягає в тому, що молодші респонденти краще розрізняли контент штучного інтелекту від людського.
Ось як розподілилися результати залежно від вікових груп:
- 18-24 роки: 61.29% правильних відповідей.
- 25-34 роки: 55.75% правильних відповідей.
- 35-44 роки: 53.49% правильних відповідей.
- 45-54 роки: 50.89% правильних відповідей.
- 54+ років: 52.63% правильних відповідей.
Проте, це може бути пов’язано з кількістю учасників, оскільки в групі 18-24 років було значно менше респондентів, ніж у групі 54+ роки.
Щодо старшого населення та їхніх труднощів з ідентифікацією контенту, створеного ШІ, додаткові відомості можна знайти в дослідженні, проведеному Baycrest Center for Geriatric Care.
Дослідники з’ясували, що з віком ми зосереджуємося на різних аспектах того, що чуємо або бачимо. Наприклад, замість того, щоб сприймати зображення як єдине ціле, доросліші учасники можуть звертати увагу на окремі особливості зображення, які роблять його реалістичнішим. Стосовно аудіо, генерованого ШІ, з віком люди схильні звертати увагу більше на слова, які говорить співрозмовник, а не на тон або інтонацію мови, які можуть бути важливими індикаторами генеративного аудіо.
Копірайтинг чи зображення — де простіше ідентифікувати ШІ

Згідно з дослідженням, людям було простіше ідентифікувати копірайтинг, згенерований ШІ, ніж зображення.
- 57.3% опитаних відрізнили текст, згенерований ШІ від людського.
- 53.36% опитаних відрізнили зображення, згенероване ШІ від створеного людиною.
При аналізі тексту, створеного штучним інтелектом, відносно легко виявити його холодну, механічну мову або ж конструкції, де ШІ надто старається здатися людиною.
Автори дослідження відмітили, що легкість виявлення текстів, створених ШІ, може почати впливати на бренди, які користуються штучним інтелектом:
«Якщо потенційний покупець читає опис продукту і визначає його як текст, створений ШІ, це може відштовхнути його від вашого бренду чи продукту, що призведе до втрати клієнта. Крім того, текст з людським елементом додає додаткові емоції та переконання, необхідні для перетворення потенційного покупця з “теплого клієнта” в “реалізований продаж”. Таким чином, контент, створений людиною, не тільки зберігає наявних клієнтів, але й допомагає залучити нових».
Результати можуть вказувати на те, що системи штучного інтелекту швидше розвиваються у візуальній сфері, ніж у сфері текстового контенту. Однак це не гарні новини, тому що візуальні обʼєкти можуть краще маніпулювати людиною. Внаслідок створення фейків фотографій та творів мистецтв, які складно відрізнити від створених людиною.
Висновки, до яких спонукає дослідження
Результати розпізнавання людиною генеративного контенту дають розуміння того, що понад половина респондентів 54.64% змогла відрізнити ШІ-контент. Однак, слід врахувати те, що респондентами були люди, ознайомлені зі сферою та специфікою роботи ШІ. Відповідно, якщо навіть ці люди мали проблеми з розпізнаванням, результати з респондентами, які не ознайомлені з ШІ потенційно можуть бути гіршими.
До речі, пройти тест, який пропонували Nexcess, та перевірити себе можна у них на сайті.
Не можна ігнорувати те, що ШІ продовжує розвиватися. Зʼявляються нові плагіни, нові мовні моделі та покращуються старі. Тому критично необхідною є система маркування ШІ-контенту та навчання, яке допоможе людям ідентифікувати генерований контент.
Якщо вам було цікаво дізнатися про дослідження, підписуйтеся на наш Телеграм-канал, де ми ділимося цікавими текстами та новинами про маркетинг, штучний інтелект, оновлення Google і не тільки.
![]()