Фишки Screaming Frog, о которых не знает SEO-junior
 Статья для продвинутых SEO-специалистов, которые ведут проекты самостоятельно и постоянно пользуются Screaming Frog. Как пользоваться эффективно? В ней – неочевидные способы применения инструмента. Custom Extraction Screaming Frog, он же парсинг, – хоть и входит в стандартный набор функционала, но не все умеют им пользоваться. А мне кажется, любому SEO-специалисту будет полезно в этом разобраться. Расскажу обо всем поэтапно и максимально понятно.
Статья для продвинутых SEO-специалистов, которые ведут проекты самостоятельно и постоянно пользуются Screaming Frog. Как пользоваться эффективно? В ней – неочевидные способы применения инструмента. Custom Extraction Screaming Frog, он же парсинг, – хоть и входит в стандартный набор функционала, но не все умеют им пользоваться. А мне кажется, любому SEO-специалисту будет полезно в этом разобраться. Расскажу обо всем поэтапно и максимально понятно.
Самые популярные функции
Благодаря Screaming Frog, мы можем выявить основные ошибки на сайте:
- Страницы с 301, 302, 307 редиректами.
- Страницы с кодом ответа 404.
- Исходящие ссылки, которые нужно закрыть в nofollow.
- Пустые, дублирующиеся, неоптимизированные метатеги TITLE, Description и заголовок H1.
- Страницы с фрагментами, которые необходимо закрыть от индексации (?sort=, ?filter= и т. д.)
Все вы, вполне возможно, встречали в блогах разных компаний, занимающихся продвижением в органическом поиске, а также в публикациях частных сеошников. В общем, ничего нового. Поэтому идем далее.
Продвинутый список ошибок и проверок
- Проверка микроразметки, ошибок и предупреждений (вкладка Structure Data). Для этого в разделе Configuration->Spider поставьте галочки:
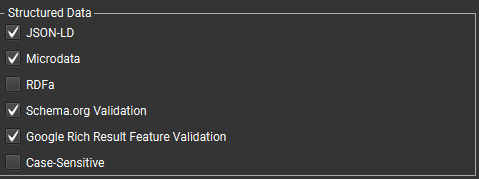
- Проверка индексирования страниц, проблемы со страницами, которые уже в индексе и др. Для этого важно, чтобы сайт был добавлен в Search Console и подключить свой гугл аккаунт в «лягушке» (так специалисты шутливо называют Screaming Frog).
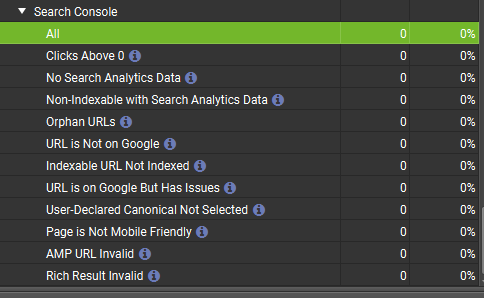 Тут нас интересуют строки:
Тут нас интересуют строки:
- URL is Not on Google – страница не в индексе.
- Indexable URL not Indexed – разрешенная страница для индексации не в индексе.
- URL is on Google But Has Issues – страница в индексе, но имеет проблемы.
Это информация, которая детальнее всего исследуется.
- Сканирование с включенным JavaScript для динамических сайтов:
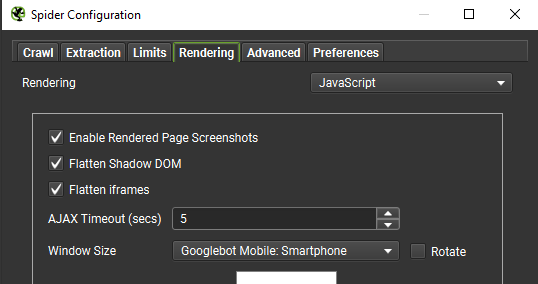 Личного опыта с такими сайтами у меня не было, но вот на примере американского сайта по поиску зубного врача мы получаем все страницы:
Личного опыта с такими сайтами у меня не было, но вот на примере американского сайта по поиску зубного врача мы получаем все страницы: 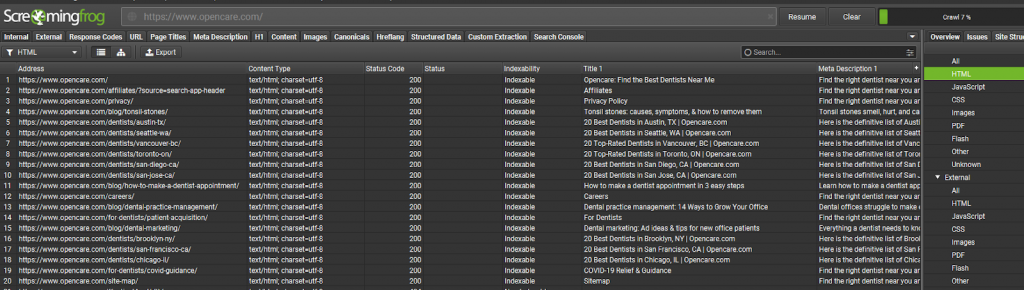
Screaming Frog: как парсить в интересах SEO
Что значит в интересах SEO? Я имею в виду, ведение некой статистики сайта, для удобного понимания – на каких страницах нужно текст доработать по объему, на какие внедрить таблицы, блоки «Вопрос-ответ» и т. д.
В моем случае это выглядит так:
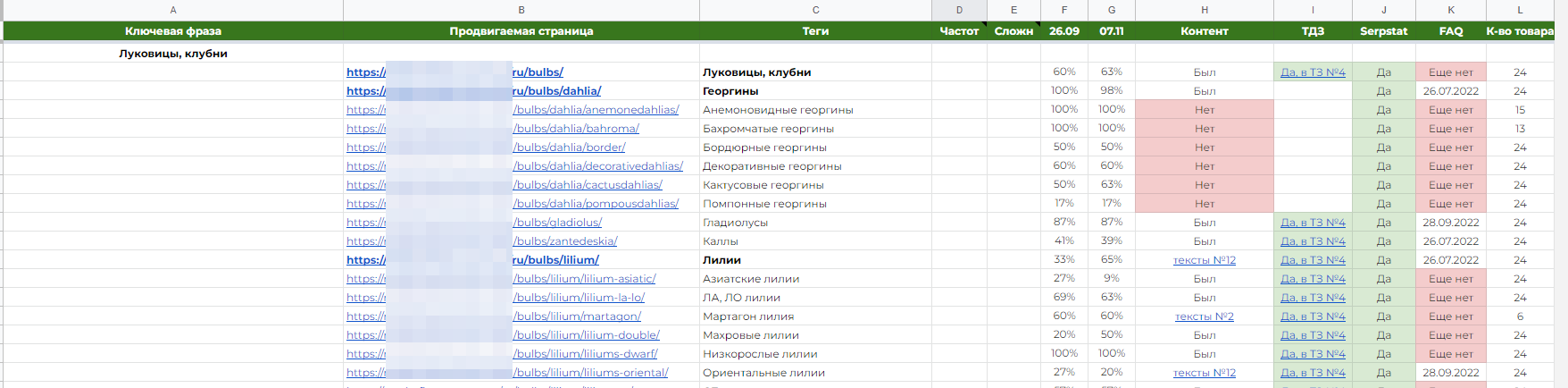
Вкратце, я веду статистику по таким параметрам:
- наличие нового или старого контента;
- наличие или отсутствию блока FAQ, и в каком он статусе (нет, внедрен и дата события, жду ответ);
- количество товара: тут я не суммировал весь товар на страницах пагинации, а брал только первую из них. Как минимум, у нас будет предположение, что плохие позиции могут быть из-за отсутствия или малого количества товара на странице.
А теперь вернемся к тому, каким образом мы будем получать эти данные.
Для начала нам понадобится любое расширение для браузера, которое работает с XPATH. Для Screaming Frog подойдет, например, Toggle XPather. Он поможет прямо на сайте видеть, правильно ли мы используем xpath путь для получения нужного элемента на сайте.
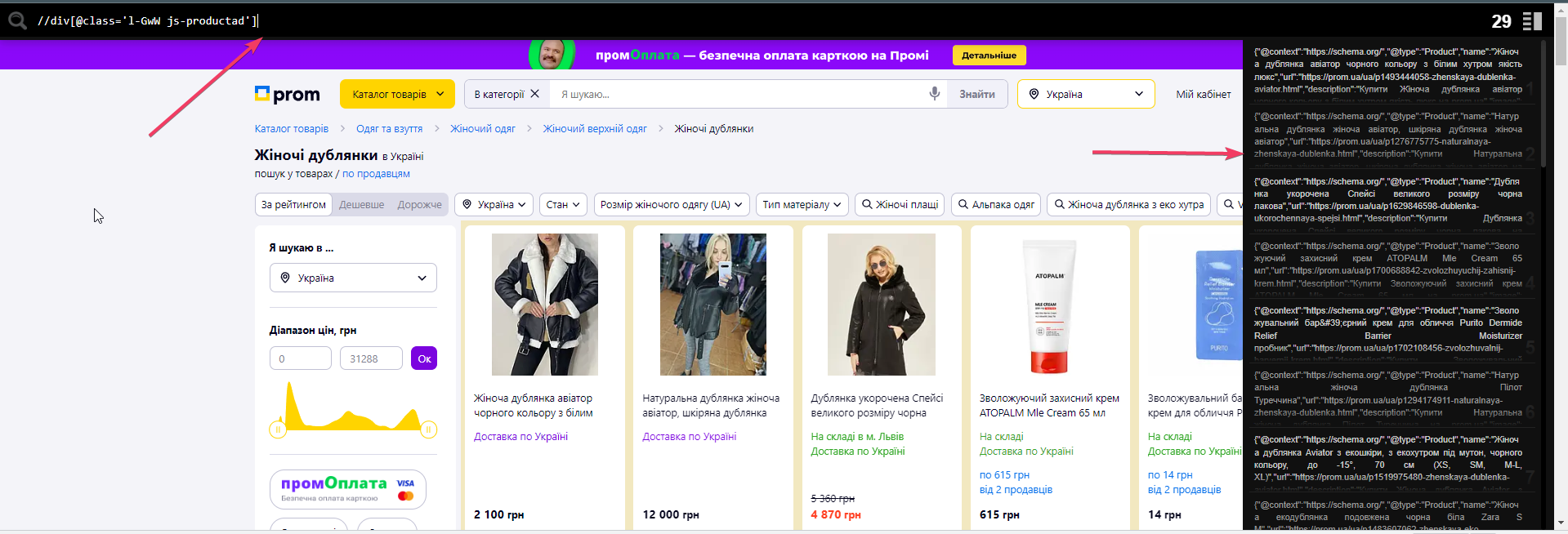
На изображении видно, что при вводе корректного xpath (в нашем случае – класс карточки товара), расширение справа выводит то, что внутри этого тега и количество таких тегов. Это визуально упрощает понимание, что в итоге нам сможет вытянуть Screaming Frog.
А теперь перейдем к тому, как парсить данные, которые есть в моей таблице.
Бонусом я покажу дополнительные варианты, которые могут быть полезными.
Парсим количество товара на странице
Для этого нам нужно взять общий class или ID для всех карточек товара. Это может быть как один из < div >, так и любой другой HTML-тег, который присутствует только на карточках и нигде больше.
Для примера возьмем сайт prom.ua
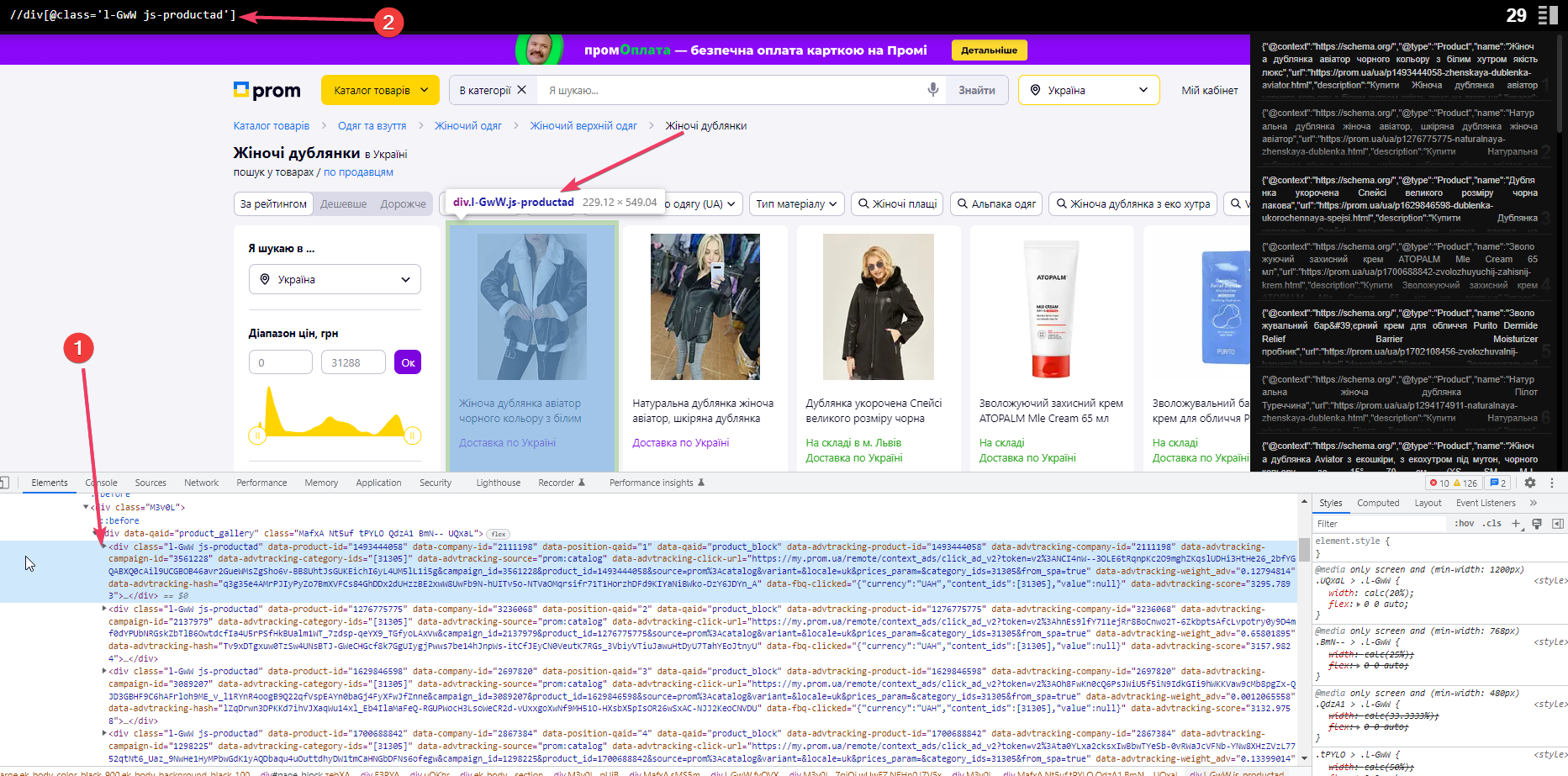
Внутри общего блока < div data-qaid=”product_gallery” class=”MafxA Nt5uf tPYLO QdzA1 BmN– UQxaL”> есть блок с классом l-GwW js-productad, который дублируется на каждой карточке. Берем его, указываем для начала в расширении – //div[@class=’l-GwW js-productad’]. Подсвечивается то, что надо, видим число 29 – это означает 29 блоков на странице.
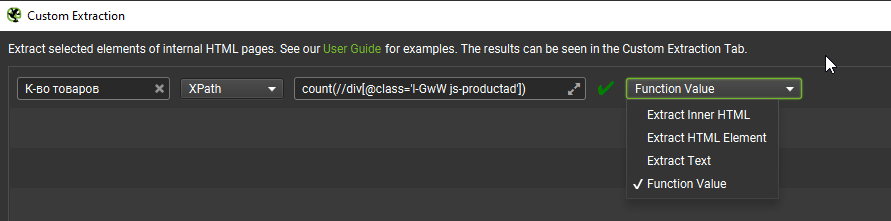
Чтобы получить только число, добавляем к формуле count(//div[@class=’l-GwW js-productad’]) и в лягушке выставляем «Function Value».
Получаем результат:

Использовать можно режим Screaming Frog SEO Spider, чтобы парсить, или List
Парсим количество символов в тексте
Расcмотрим на примере Barb.ua
Находим блок и его класс, где находится текст. Но подсвечивается два вместо одного. Значит, где-то есть такой же блок.
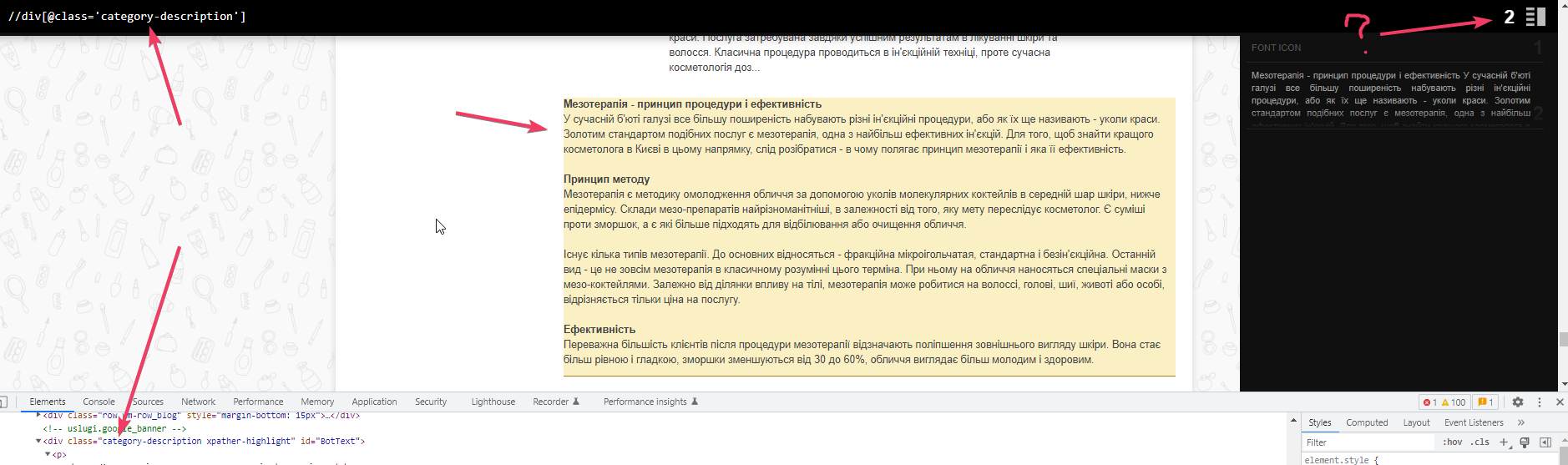
Да, вот он. Именно из-за него просто спарсить не получится, нужно разобраться.
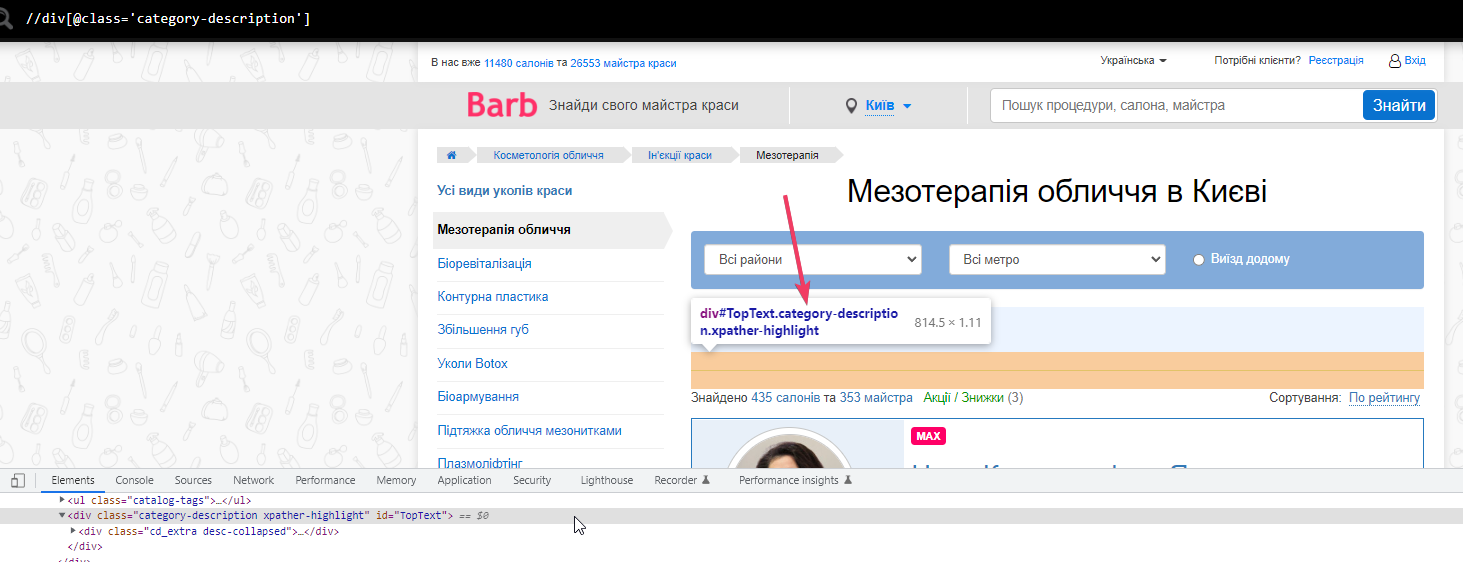
Поэтому пытаемся достать через ID, он здесь уникальный (как и в 95% других случаев).

Достаем текст через id=”TopText” но получаем длину всего 244 символа. Хотя если проверить, то текста там на 1400 символов
Немного внимательности и знаний xpath. Я нашел два варианта, которые дадут нам корректные данные. Делюсь:
Вариант №1. string-length((//div[@class=’category-description’])[2]) – через класс, но с уточнением именно про второй блок. Обратите внимание на конструкцию и на будущее запомните – точно пригодится и упростит жизнь.
![На скрине я убрал функцию подсчета, чтобы просто визуально показать, что [2] работает](https://inweb.ua/blog/wp-content/uploads/2022/12/na-skrine-ya-ubral-funktsiyu-podscheta-chtoby-prosto-vizualno-pokazat-chto-2-rabotaet.png)
На скрине я убрал функцию подсчета, чтобы просто визуально показать, что [2] работает
Вариант №2. string-length(//div[@id=’BotText’]/p) – поскольку в данном случае после < div > весь текст находится в < p& gt;:

Если вам нужен сам текст, а не его количество символов, нужно:
- В настройках Custom Extraction заменить «Function Value» на Extract Inner Html.
- Из конструкции убрать string-length.
И получаем размеченный тегами текст, который вы можете использовать на свое усмотрение:

А что бы еще спарсить… ? Подкидываю несколько идей
Блок с перелинковкой
Тут нам нужен родительский блок + обращение к дочерним блокам + @href если нужна только ссылка или просто //a – если нужен текст ссылки. Обратите внимание, что у каждого сайта классы тегов уникальны. В конце статьи я покажу несколько стандартных решений.
//div[@class=’M3v0L Tr1FH C6zKA NR0J4 MuCm8′]//div[@class=’l-GwW’]//@href
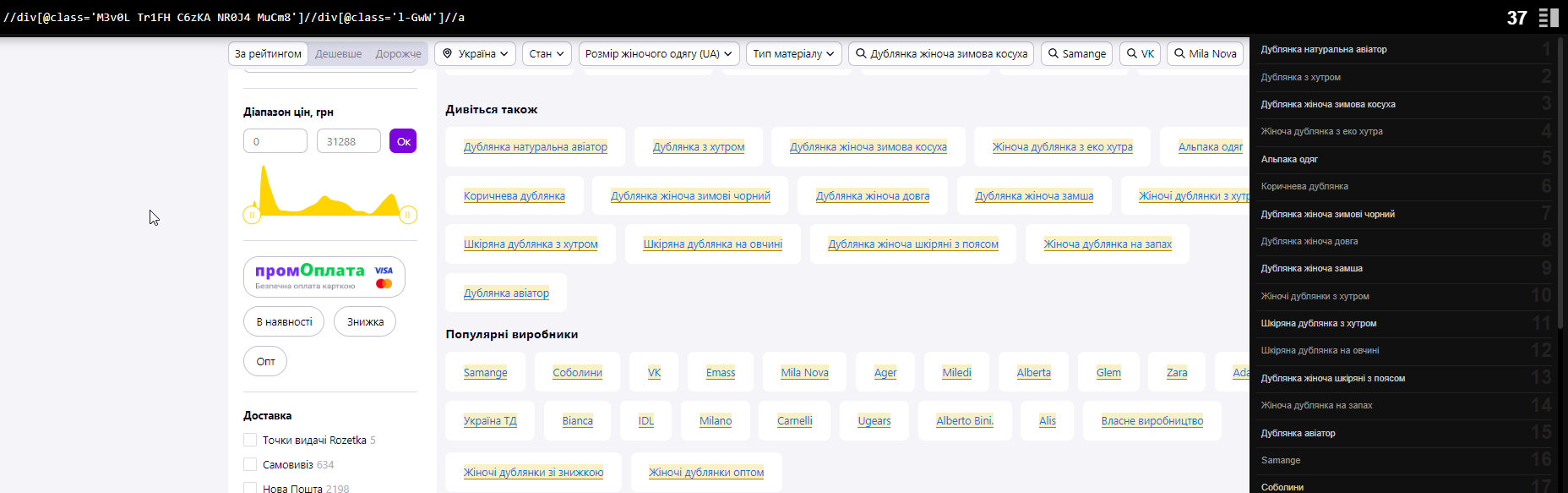
Если нужно просто узнать, есть ли такой блок и его количество, повторяем то же самое, что и с товаром.
count(//div[@class=’M3v0L Tr1FH C6zKA NR0J4 MuCm8′])
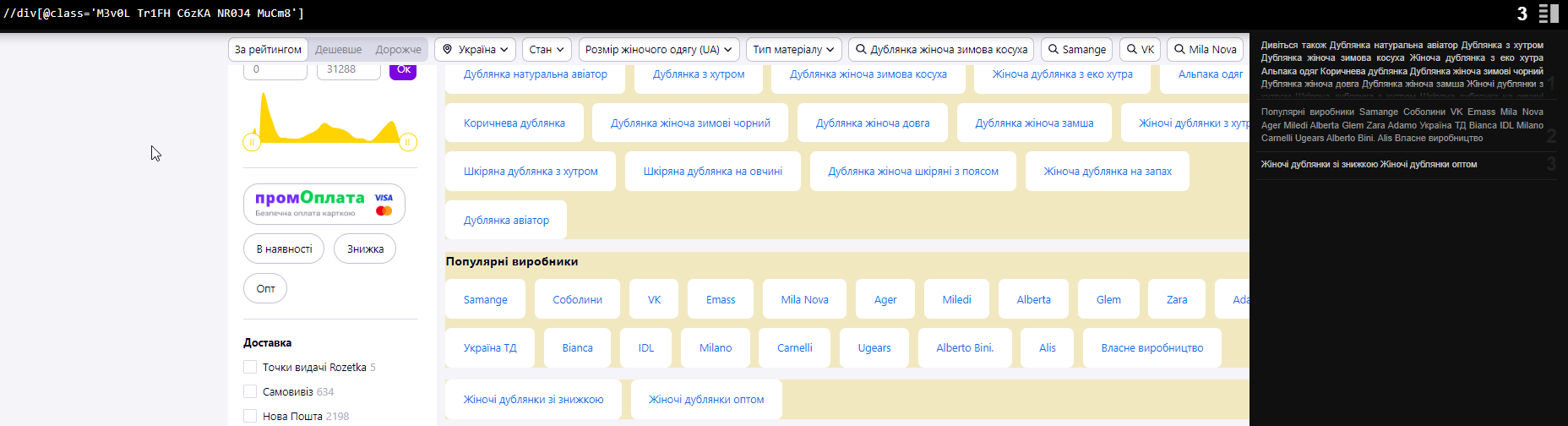
… и получаем количество таких блоков
Содержимое контента для нахождения нужного ключа\слова
Допустим, вам нужно спарсить определенные имена специалистов или просто найти слово, которое вы забыли перевести с русского на украинский язык, где-то в контенте. Тут приходит на помощь конструкция [contains(p, ‘word’)]. Где вместо «p» мы указываем нужный нам HTML-тег или ставим просто «.» , чтобы искать в любых тегах и вместо word 00 искомое слово, символ. Например, нужно найти украинские буквы «і, ї, є».
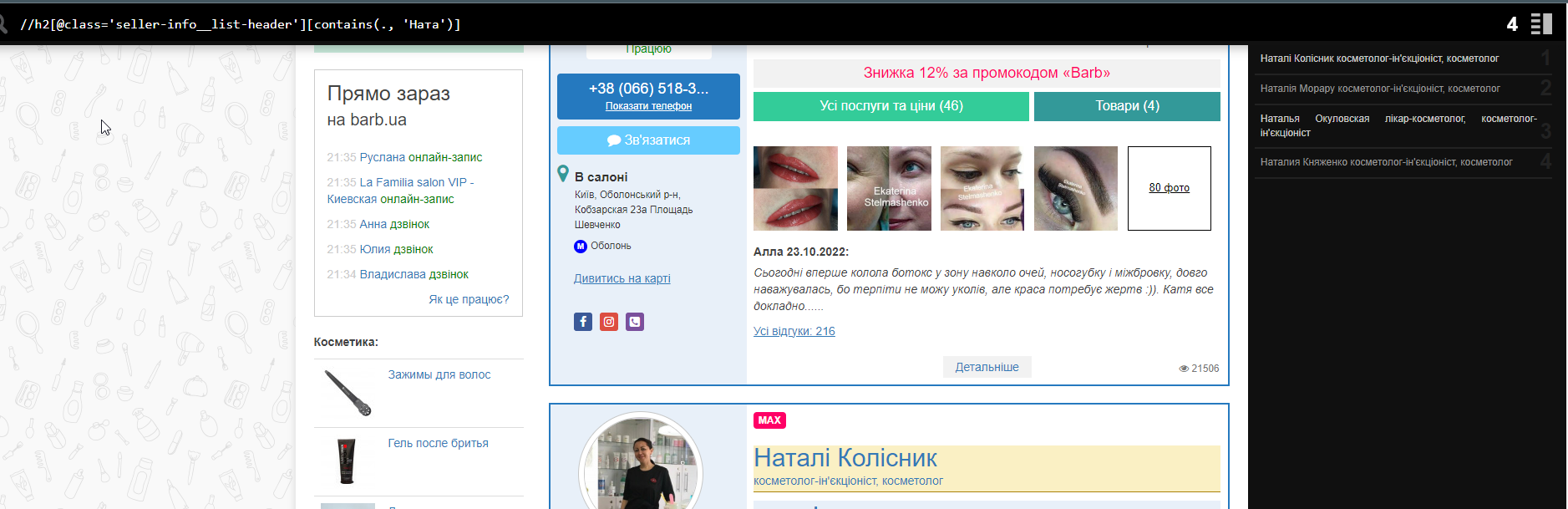
Можно так: //h2[contains(., ‘Натал’)] или //h2[@class=”seller-info__list-header”][contains(.,”Натал” )]
Дата кеша страницы в Google
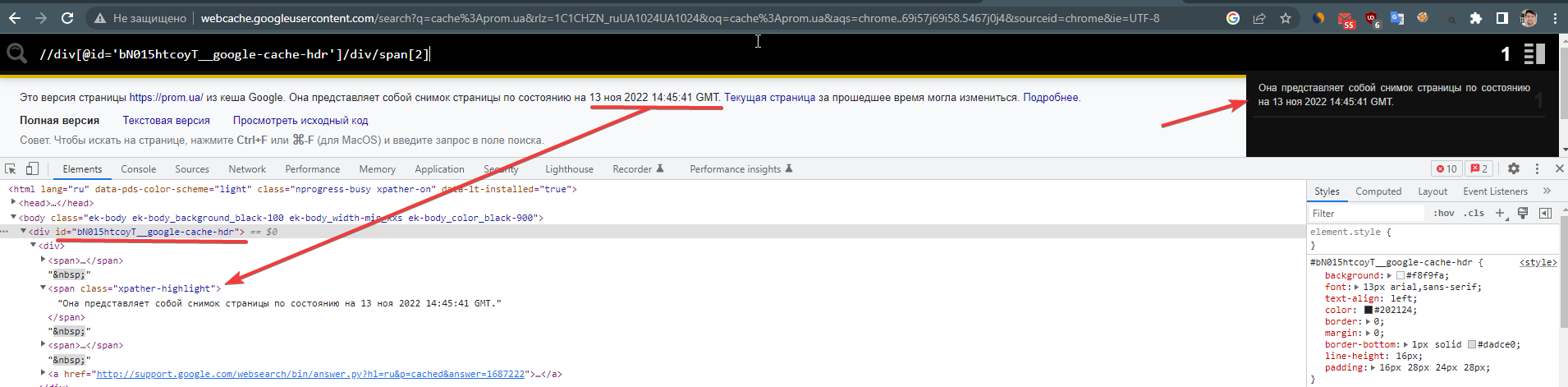
Для этого нам нужен ID блока < div > и второй по списку для получения более короткого предложения.
//div[@id=’bN015htcoyT__google-cache-hdr’]/div/span[2] – готовая формула.
Берем список нужных нам страниц, добавляем в Excel сцепляем ссылки с формулой http://webcache.googleusercontent.com/search?q=cache и отправляем в Screaming Frog:

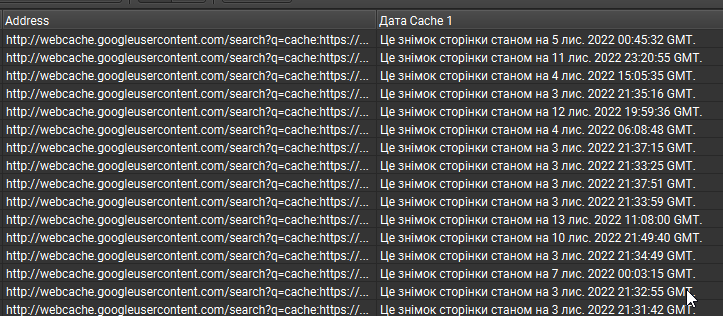
Важно! Такую же таблицу мы можем получить и с помощью формул в Google Sheets. Проблема в том, что там постоянно во многих ячейках показывает Н\Д. Если есть варианты, как можно этого избежать для большого количества страниц, буду рад рассмотреть и, возможно, использовать в будущем. Пишите в комментарии, я обязательно отвечу.
Шпаргалки (как и обещал)
- Таблички с готовыми методами парсинга с помощью Xpath и Regex (регулярные выражения).
- Официальный гайд по парсингу.
Заключение
Благодаря умениям парсить сайты с помощью относительно бесплатной Screaming Frog, мы можем доставать много важной информации и использовать в различных целях. Можем:
- наполнить сайт чужим контентом, но мы знаем, что это делать нежелательно:
- вести статистику по своему или клиентскому проекту;
- использовать при нахождении/добавлении фишек, которые заметили у конкурента и много чего другого.
Решать только вам.
И для тех, кому реально интересно! Как можно выгрузить дату кеша еще короче? Чтобы только число и год были? Варианты оставляйте в комментариях! Будет интересно!
