Витік даних Google Search Ranking 2024: все, що необхідно знати SEO-спеціалісту
У травні 2024 року стався масштабний витік внутрішніх документів Google, який спричинив хвилю обговорень серед SEO-спеціалістів. Ці документи містять детальну інформацію про дані, які збирає Google, і як вони можуть використовуватися в алгоритмах ранжування.
Ми вирішили зібрати всю інформацію щодо витоку в одній статті. А також проаналізувати деякі з тверджень із витоку, щоб допомогти SEO-спеціалістам.

Передісторія витоку та його об’єми
Витік даних Google стався після випадкової публікації внутрішньої документації API Content Warehouse на репозиторії GitHub. Ця помилка була швидко виправлена 7 травня 2024 року, проте автоматичні сервіси документації встигли зберегти ці дані, що призвело до їх розповсюдження серед SEO-спеціалістів.
Спочатку про витік повідомили такі відомі експерти, як Ренд Фішкін та Майк Кінг. Пізніше Google підтвердив автентичність документів, зазначивши, що деяка інформація може бути застарілою або вирваною з контексту.
Основні моменти:
- Дата витоку: травень 2024 року.
- Усі документи витоку: оригінал.
- Обсяг витоку: 2 500 сторінок.
- Наповнення витоку: 14 014 атрибутів, які стосуються ранжування та маркування контенту у Google.
- Реакція Google: підтвердження автентичності, застереження щодо інтерпретації даних.
Цей витік став справжнім потрясінням для SEO-спільноти, оскільки деталі, зазначені у ньому, розкривають, як працюють внутрішні механізми Google, а у деяких моментах суперечать попереднім даним від Google.
Хоча частина інформації може бути застарілою, все ж вона дає свіжий погляд на алгоритми та методи, які використовує Google для ранжування сторінок.
Що містить витік даних Google Search Ranking 2024

Внаслідок витоку в інтернет потрапило понад 2500 внутрішніх документів Google, що містять детальну інформацію про алгоритми ранжування пошуку. У цих документах було виявлено 14 014 атрибутів, які використовуються для оцінки та ранжування сторінок.
Витік дає свіжий погляд на те, як Google збирає, обробляє та використовує дані для формування результатів пошуку. Проте зробити оцінку даним з витоку складно, оскільки це технічна інформація.
І виглядає вона наступним чином:

Витік описує кожен модуль API та розбиває їх на резюме, типи, функції та атрибути. Здебільшого ми розглядаємо визначення властивостей різних буферів протоколів (або протобуфів), до яких отримують доступ системи ранжування для генерації SERP (Search Engine Result Pages).
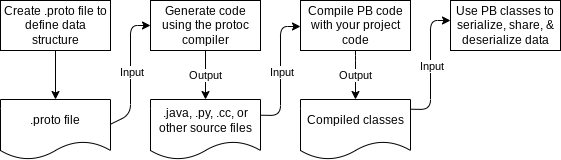
Основні типи даних, які опинилися у витоку:
- Дані про контент: як Google аналізує якість контенту, які сигнали визначають оригінальність та якість сторінки.
- Які фактори залучаються в оцінці тексту — розмір шрифту термінів та наявність виділень жирним.
- Як оцінюється якість посилань, чи залежить вона від джерела, анкору.
- Як аналізується швидкість появи посилань і як визначається наявність спамних анкорних посилань.
- Дані про те, як вливає на ранжування тривалість перебування користувачів на сторінці та кліки, зібрані з браузера Chrome.
- Як час взаємодії визначає успішність сесії пошуку.
Значення для SEO-спеціалістів та суперечності
Попри суперечності між SEO-спеціалістами, цей витік даних має величезне значення для розуміння роботи SEO.
По-перше, він підтверджує існування багатьох факторів, про які Google раніше не згадував або навіть спростовував їхню важливість.
Наприклад, використання кліків та даних про поведінку користувачів для ранжування сторінок багато обговорювали у SEO-спільноті. Раніше Google заявляв, що такі дані не використовуються напряму для ранжування, але витік показав, що існує система NavBoost, яка враховує ці сигнали.
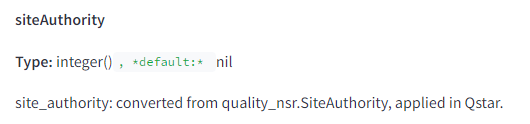
Крім того, витік підтверджує існування метрики siteAuthority, що оцінює авторитетність сайту. Це особливо важливо, оскільки Google завжди заперечував використання загальної метрики авторитетності домену, що стало причиною численних дискусій серед SEO-спеціалістів.
Витік також містить інформацію про різні обмежувальні алгоритми, такі як зниження рейтингу для доменів з точним збігом ключових слів (exactMatchDomainDemotion) та зниження рейтингу для посилань з невідповідним анкорним текстом (anchorMismatch). Ці деталі допомагають краще розуміти, які практики можуть негативно впливати на ранжування сайту.
Також ця інформація підкреслює важливість створення якісного контенту під болі користувачів, оскільки Google активно використовує дані про взаємодію для оцінки сторінок. Користувачі, які проводять більше часу на сторінці та взаємодіють з контентом, надають позитивні сигнали, а це покращує рейтинг сайту.
Хоч Google визнав витік автентичним, багато спеціалістів та й сама компанія закликає ставитися до цієї інформації з обережністю. Документи можуть містити застарілі або вирвані з контексту дані, що може призвести до неправильних висновків.
Крім того, Google завжди захищає свої алгоритми від маніпуляцій, тому деякі із сигналів у витоку можуть бути збережені лише для внутрішнього використання і насправді не мати впливу на фактичне ранжування.
Аналіз витоку даних Google Search Ranking 2024

З повним обʼємом витоку можна ознайомитися на сайті Dixon Jones, де зібрали всі 14 014 атрибутів, також можна скористатися ботом у GPT Google Search Ranking 2024, який створили на основі цих даних, аби детальніше дізнатися про конкретні моменти.
Якщо вам простіше сприймати інформацію візуально, можна ознайомитися з візуалізацією даних витоку.
Що спростували дані з витоку Google
Ми розберемо деякі пункти з витоку, які суперечать раннім заявам експертів Google.
1. Google може використовувати кліки для ранжування
Google завжди наполягав, що кліки користувачів не є фактором ранжування. Проте витік даних показав існування системи NavBoost, яка використовує клікові сигнали для коригування позицій у пошуковій видачі.
Витік виявив, що NavBoost враховує різні типи кліків, такі як довгі кліки (long clicks), останні кліки (last clicks) і «добрі» кліки (good clicks).

Крім того, документація представляє користувачів як виборців, а їхні клацання зберігаються як їхні голоси. Система підраховує кількість невдалих кліків і сегментує дані за країнами та пристроями.
Вони також зберігають, який результат мав найдовше клацання протягом сеансу. Тому користувачам потрібно провести значну кількість часу на сторінці. Довгі клацання є показником успішності сеансу пошуку, як і час очікування, але в цій документації немає спеціальної функції під назвою «час перебування».
Це свідчить про те, що Google використовує дані про поведінку користувачів для оцінки якості результатів пошуку, що суперечить їхнім попереднім заявам.
2. Використання Domain Authority
Google заперечував використання метрики Domain Authority, стверджуючи, що вона не є частиною їхнього алгоритму.
Проте, витік даних виявив метрику siteAuthority, яка вимірює загальну авторитетність сайту. Ця метрика використовується для визначення початкового значення нових сторінок до того, як вони наберуть власний PageRank.
Це підтверджує, що Google все ж використовує оцінку авторитетності сайту, подібну до Domain Authority, для визначення релевантності контенту.
3. Використання даних з браузера Chrome
Google стверджував, що не використовує дані з браузера Chrome для оцінки якості сторінок. Однак витік показав, що Google відстежує перегляди сайтів через Chrome і використовує ці дані для ранжування.

Зокрема, атрибут chromeInTotal враховує кількість переглядів сайту користувачами Chrome.
Це означає, що дані з браузера Chrome можуть впливати на оцінку якості та релевантності сторінок у пошуковій видачі.
4. Пісочниця для нових сайтів
Google завжди заперечував існування «пісочниці» для нових сайтів, яка обмежувала б їхні можливості для ранжування на початкових етапах. Проте, витік даних показав, що атрибут hostAge використовується для «пісочниці» нових сайтів, щоб запобігти спаму.
Це обмеження допомагає запобігти маніпуляціям з SEO і потребує, щоб сайти довели свою якість та надійність перед тим, як отримати високі позиції у пошукових результатах.
Це підтверджує існування механізму, який обмежує можливості нових сайтів у перші місяці їхнього існування, поки вони не здобудуть достатньо довіри та авторитету.
Інсайти з витоку
Окрім спростувань, у витоку можна знайти цікаві інсайти, які можуть допомогти покращити показники сайтів та свого контенту у видачі. Деякі з таких інсайтів зібрали нижче.
Значення авторства контенту
Однією з ключових тем, виявлених у витоку, є важливість авторства контенту.
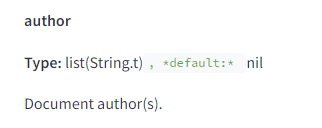
Хоча Google раніше заперечував значну роль авторства в ранжуванні, документи показали наявність атрибута author, який визначає авторів документів. Крім того, Google може визначити, чи є вказаний на сторінці автор реальним автором контенту за допомогою атрибута isAuthor.
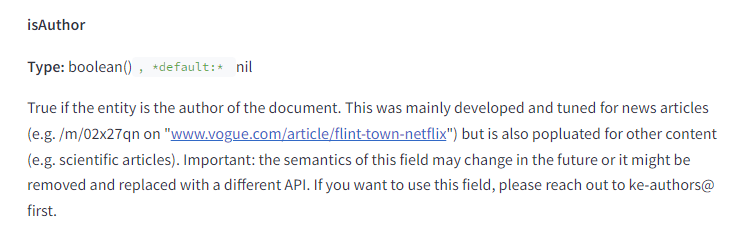
Це означає, що створення авторитетного авторського профілю і забезпечення якісного контенту від відомих авторів може позитивно впливати на ранжування сайту та сторінки.
Демотиваційні фактори
Також у даних можна виявити низку алгоритмічних демотиваційних факторів, які можуть негативно впливати на позиції сайту в пошуковій видачі.
До цих факторів можна віднести:
- Anchor Mismatch: неправильне узгодження анкорного тексту з цільовим сайтом може призвести до зниження значення посилання.
- SERP Demotion: показники на основі поведінки користувачів на сторінці результатів пошуку, які можуть свідчити про незадоволення користувачів.
- Nav Demotion: демотивація через погану навігацію на сайті або проблеми з UX.
- Exact Match Domains Demotion: зниження значення доменів з точним збігом ключових слів, про що було відомо ще в 2012 році.
- Product Review Demotion: специфічна демотивація для сайтів з низькоякісними відгуками про продукти.
- Location Demotion: демотивація сторінок, які не відповідають локальному контексту пошуку.
- Porn Demotion: демотивація через наявність контенту для дорослих.
Використання дати публікації
Витік показав, що Google приділяє велику увагу датам публікації та оновлення контенту.
Алгоритми використовують кілька типів дат:
- bylineDate: дата, явно вказана на сторінці.
- syntacticDate: дата, витягнута з URL або заголовка.
- semanticDate: дата, отримана з вмісту сторінки.
Це означає, що підтримка актуальності контенту та регулярне оновлення дат публікації можуть позитивно впливати на ранжування. Важливо забезпечити відповідність дат у всіх структурованих даних, заголовках та XML-сайтах.
Збереження даних про реєстрацію домену
Google зберігає інформацію про реєстрацію доменів, включаючи дату створення та останнє продовження домену. Це підтверджує теорію, що статус реєстрації домену може впливати на ранжування.
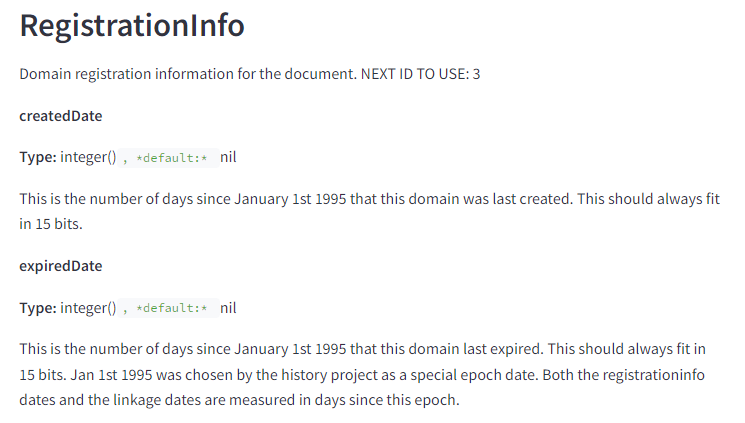
Також це може використовуватися для виявлення зловживань, пов’язаних з використанням прострочених доменів.
Відмінності у фокусі на відео
Якщо понад 50% сторінок на сайті містять відеоконтент, сайт вважається відеофокусованим і ранжується за іншими правилами.

Це означає, що для відеоконтенту діють інші алгоритми та критерії оцінки якості, що важливо враховувати при розробці стратегії контенту.
Оцінка Your Money Your Life (YMYL) контенту
Google має спеціальні класифікатори для оцінки YMYL контенту, зокрема для здоров’я та новин.
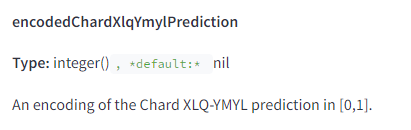
До такого контенту висуваються підвищені вимоги щодо якості та надійності, щоб забезпечити безпеку та корисність для відвідувачів.
Google особливо уважно оцінює YMYL-матеріали для забезпечення стандартів E-E-A-T.
Витік підтвердив, що YMYL оцінюється на рівні окремих блоків інформації (абзаців, речень або навіть окремих фраз), а не на рівні всієї сторінки. Це вказує на те, що система використовує вбудовування (embeddings) для аналізу та розуміння змісту цих блоків.
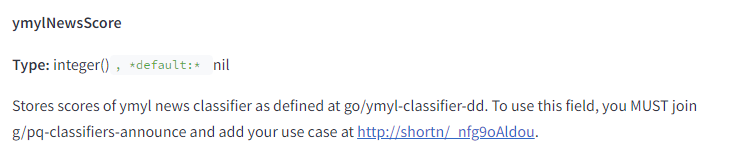
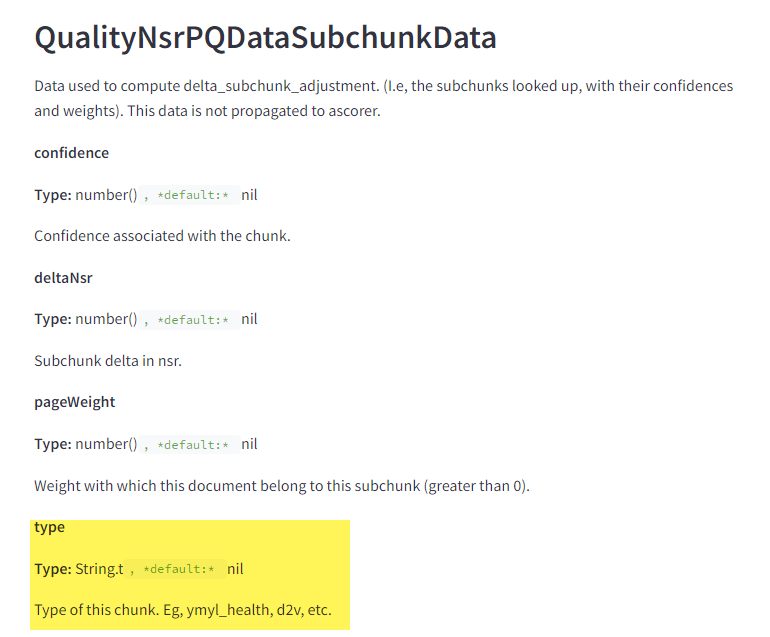
Це підтверджує важливість якісного контенту в цих тематиках та суворіші вимоги до достовірності та авторитетності такого контенту.
У Google є «документи золотого стандарту»
Документи, позначені як «золотий стандарт», використовуються для надання додаткової ваги контенту, який оцінений людьми, а не автоматичними алгоритмами.

Це може означати, що якість контенту, оцінена людьми, має особливе значення для алгоритмів ранжування Google.
Ще кілька цікавих знахідок із витоку
- Рівень індексації впливає на значення посилання. Метричний показник sourceType показує зв’язок між рівнем індексації сторінки та її цінністю. Чим вище рівень індексації (тобто, сторінка знаходиться в «топовому» шарі, оновлюється регулярно і зберігається в flash memory), тим ціннішими є посилання з неї. Отже, посилання зі «свіжих» або високо індексованих сторінок мають більшу цінність для покращення ранжування.
- Google враховує PageRank домашньої сторінки для всіх сторінок сайту, використовуючи його як тимчасовий показник для нових сторінок, поки вони не отримають власний PageRank. Це і siteAuthority можуть слугувати проксі для нових сторінок на початку їх індексації. Довіра до домашньої сторінки також впливає на цінність посилань. Тому важливо зосереджуватися на якості та релевантності посилань, а не на їх кількості.
- Google обмежує кількість токенів, які можуть бути враховані для документа, зокрема в системі Mustang. Тому авторам варто розміщувати найважливіший контент на початку тексту.

- Google використовує метрики для виявлення сплесків спамних анкорних текстів, зокрема, функцію phraseAnchorSpamDays, що дозволяє вимірювати швидкість появи спам-посилань. Це може використовуватися для виявлення спамних сайтів і нейтралізації SEO-атак, не враховуючи ці посилання при оцінці сайту.
- Показник OriginalContentScore вказує на те, що короткий контент оцінюється за його оригінальністю, тому якість контенту не завжди залежить від довжини. Також існує показник для виявлення перенасичення ключовими словами.
- У документації немає метрики для підрахунку довжини заголовків сторінок або фрагментів. Єдиний показник, snippetPrefixCharCount, визначає, що може бути використано у фрагменті. Це підтверджує, що довгі заголовки сторінок не є оптимальними для залучення кліків, але вони можуть бути корисними для ранжування.

- Google зберігає всі версії проіндексованих сторінок, але при аналізі посилань враховує лише останні 20 змін URL-адреси. Це пояснює, чому не можна просто перенаправити сторінку на нерелевантний об’єкт і очікувати збереження цінності посилання. Щоб досягти «чистого листа» в Google, необхідно змінювати сторінки та домагатися їх повторної індексації не менше 20 разів.
- Документація вказує на існування показника titlematchScore, який оцінює відповідність заголовка сторінки запиту. Це означає, що Google досі надає значення тому, наскільки добре заголовок сторінки відповідає запиту. Тому варто розміщувати цільові ключові слова на початку заголовка.
- Розмір шрифту термінів і посилань має значення для SEO. Google відстежує середній ваговий розмір шрифту термінів у документах, а також анкорного тексту посилань. Це підтверджує, що виділення тексту, яке практикувалося в SEO з 2006 року, досі є актуальним.

- Дані про відмову від посилань (disavow) не згадуються в API, що вказує на їх відокремленість від основних систем ранжування. Це підтверджує, що функція disavow використовується для навчання класифікаторів спаму Google. Відсутність даних про відмову «онлайн» підтримує цю гіпотезу і вказує на необхідність перегляду підходів до побудови посилань.
Twiddlers у контексті витоку даних Google Search Ranking 2024
Витік даних Google Search Ranking 2024 показав, що Twiddlers відіграють важливу роль у корекції результатів пошуку. До цього витоку їх значення було маловідоме.
Twiddlers можуть включати такі функції, як обмеження кількості результатів певного типу у видачі.
Twiddlers, виявлені у документації:
- NavBoost: функція повторного ранжування на основі кліків користувачів.
- QualityBoost: функція покращення якості контенту.
- RealTimeBoost: функція покращення результатів у реальному часі.
- WebImageBoost: функція покращення результатів пошуку зображень.
Twiddlers впливають на кінцеве ранжування сторінок. Наприклад, NavBoost може підвищити позицію сторінки з високою активністю кліків і довгим часом перебування користувачів. Це підкреслює важливість покращення користувацького досвіду та залучення відвідувачів.
Наслідки витоку для SEO-стратегії

Майк Кінг зазначив, що SEO — це головоломка, яка постійно вдосконалюється і SEO-спеціалісти знають, як працювати з цією головоломкою. Цей витік даних хоч і мав багато відгуків як серед закордонної, так і серед української SEO-спільноти, проте основна його частина лише підтвердила здогадки експертів, а не кардинально змінила їх.
Для ефективних стратегій SEO необхідно враховувати багато чинників: від розміру шрифту до профілю посилань, аналізувати оновлення, бути у контексті змін Google. Це не змінюється роками, тож як ніколи актуальним є звернення до SEO-професіоналів.
Ми в агенції digital-маркетингу Inweb маємо досвід та кейси, які підтверджують ефективність наших стратегій та професіоналізм SEO-спеціалістів, тож ви можете покластися на нас для розробки якісної стратегії у 2024 році.
