Повне керівництво по використанню файлу Robots.txt

Що таке Robots.txt?
Robots.txt — текстовий файл, в якому вказуються правила сканування сайту для пошукових систем. Файл знаходиться в кореневій папці і є звичайним текстовим документом в форматі .txt.
Пошукові системи спочатку сканують вміст файлу Robots.txt і тільки потім інші сторінки сайту. Якщо файл Robots.txt відсутня – пошуковим системам дозволено сканувати всі сторінки сайту.
Содержание
Для чого потрібен файл Robots.txt
- Вказати пошуковим системам правила сканування і індексації сторінок сайту. Для кожного пошукача можна задати як різні правила, так і однакові.
- Вказати пошуковим системам посилання на xml-карту сайту, щоб роботи могли без проблем її знайти і просканувати.
Основним завданням robots.txt є управління доступу до сторінок сайту пошуковим системам і іншим роботам. На сайті може перебувати конфіденційна інформація, наприклад, особисті дані користувачів або внутрішні документи компанії. Завдяки директивам в файлі Robots.txt можна заборонити до них доступ пошуковим системам і їх не знайдуть.
Варто пам’ятати про те, що для Google вміст файлу є рекомендацією по скануванню сайту. Тобто, якщо сторінка закрита в файлі Robots.txt, вона все одно може потрапити в індекс пошукової системи Google, адже для нього це рекомендації по скануванню, а не індексації.
Щоб не допустити індексації певних сторінок сайту потрібно використовувати метатег robots або X-Robots-Tag.
Як створити текстовий файл Robots.txt
- Створіть текстовий документ у форматі .txt.
- Поставте йому ім’я robots.txt.
- Вкажіть вміст файлу.
- Додайте його в кореневий каталог сайту, щоб він був доступний за адресою /robots.txt.
- Перевірте коректність файлу через інструмент Google.
Файл Robots.txt повинен обов’язково знаходитися за адресою robots.txt. Якщо він буде розміщений по іншому url-адресою, пошукова система буде його ігнорувати і вважати, що все дозволено для сканування і індексації.

Вірно:
https://inweb.ua/robots.txt
Невірно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярних CMS є плагіни для редагування файлу Robots.txt:
- WordPress – Clearfy Pro.
- Opencart – редактор Robots.txt .
За допомогою зазначених модулів можна легко змінювати директиви через адміністративну панель, без використання ftp.
Вимоги до файлу Robots.txt
Щоб пошукові системи виявили і слідували директивам необхідно дотримуватись наступних правил:
- Розмір файлу не перевищує 500кб;
- Це TXT-файл з назвою robots – robots.txt;
- Файл розміщений в кореневому каталозі сайту;
- Файл доступний для роботів – код відповіді сервера – 200. Перевірити можна за допомогою сервісу або інструментів Google Search Console.
- Якщо файл не відповідає вимогам – сайт вважається відкритим для сканування і індексації.
Якщо ж пошукова система, при запиті файлу /robots.txt, отримала код відповіді сервера відмінний від 200 – сканування сайту припиниться. Це може істотно погіршити швидкість сканування сайту.
Обмеження документа Robots.txt
- Не всі пошукові системи обробляють директиви у файлі Robots.txt однаково. У кожної є своя інтерпретація. При складанні правил слід на це звертати увагу.
- Кожна директива повинна починатися з нового рядка.
- У кожної пошукової системи є кілька роботів, які сканують сайти. Деякі з них інтерпретують правила robots.txt інакше.
- У файлі Robots.txt дозволяється використовувати тільки латинські літери. Якщо у вас кириличні url-адреси або домен – необхідно використовувати punycode.
Розглянемо на прикладі, як Robots.txt використовує систему кодування:
Вірно:
User-agent: *
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
Не вірно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Позначення і види директив
Нижче розглянемо які є директиви у файлі Robots.txt
- User-agent — вказівка пошукового бота, до якого застосовуються правила. Щоб вибрати всіх роботів – вкажіть “*”. Директива є обов’язковою для використання, без вказівки User-gent не можна використовувати будь-які правила.Наприклад:User-agent: * # правила для всіх.
User-agent: Googlebot # правила тільки для Google. - Disallow — директива, яка забороняє сканування певних сторінок або розділів.Наприклад:Disallow: / order / # закриває всі сторінки, які починаються з / order /.
Disallow: / * sort-order # закриває всі сторінки, які містять фрагмент “sort-order”.
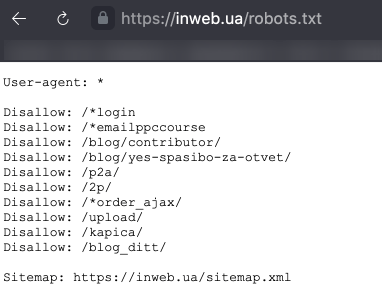
Disallow: / secretiki / # закриває всі сторінки, які починаються з / secretiki /. - Sitemap — вказівка посилання на xml-карту сайту. Якщо xml-карт сайту кілька – можна вказати їх все. Наприклад:Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb.ua/sitemap-images.xml - Allow — дозволяє відкрити для робота сторінку або групу сторінок.Наприклад:Disallow: /category/
Allow: /category/phones/
Ми закриваємо всі сторінки, які починаються з / category /, але відкриваємо /category/phones/ - Спецсимволи:* – позначає будь-яку кількість символів.Наприклад:Disallow: * # забороняє сканування всього сайту.
Disallow: * limit # Забороняє сканування всіх сторінок, які містять “limit”.
Disallow: / order / * / success / # забороняє сканування всіх сторінок, які починаються з / order /, потім містять будь-яку кількість символів, а потім / success /. - $ – позначає кінець рядка. Наприклад:Disallow: /*order$ #забороняє сканування всіх сторінок, які закінчуються на order.
У якому порядку виконуються правила
Google обробляє директиви Allow і Disallow не по порядку, в якому вони вказані, а спочатку сортує їх від короткого правила до довгого, а потім обробляє останнім відповідне правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Буде прочитана як:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким чином, якщо перевіряється посилання виду: /wp-content/uploads/file.jpg, правило “Disallow: / wp-” посилання заборонить, а наступне правило “Allow: * / uploads” її дозволить і посилання буде доступна для сканування.
У разі, якщо директиви рівнозначні або суперечать один одному:
User-agent: *
Disallow: /admin
Allow: /admin
Пріоритет віддається директиві Allow.
Приклади використання файлу Robots.txt
Приклад №1 – повністю закрити сайт від індексації.
User-agent: *
Disallow: /
Приклад №2 – блокуємо доступ до папки для Google, іншим пошуковим системам відкриваємо.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
Приклад №3 – сайт повністю відкритий для індексації.
User-agent: *
Disallow:
Приклад №4 – закриваємо всі сторінки сайту, які містять фрагмент url-адреси “secret”.
User-agent: *
Disallow: *secret
Приклад №5 – для Google відкриємо тільки папку /for-google/
User-agent: Googlebot
Disallow: /
Allow: /for-google/
Найбільш поширені помилки
Розглянемо найбільш поширені помилки, які допускають SEO-фахівці при складанні директив.
- Відсутність на самому початку директиви зірочки. Варто пам’ятати, що обов’язково потрібно додавати * перед фрагментом url-адреси, якщо директива містить фрагмент, який знаходиться не на початку url-адреси.
Наприклад, потрібно закрити від сканування url-адреса
https://inweb.ua/catalog/cateogory/?sort=name
Невірно: Disallow: ?sort=
Вірно: Disallow: /*sort= - Директива, крім неякісних url-адрес, забороняє сканування якісних сторінок. При написанні директив варто вказувати їх максимально чітко, щоб навіть теоретично якісні url-адреси не потрапили під заборону.
Невірно: Disallow: *sort
Вірно: Disallow: /*?sort=
У першому випадку, випадково можуть бути сторінки виду:
https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Адже, теоретично, деякі сторінки можуть містити в url-адресу фрагмент “sort”. - Сторінки одночасно закриті в файлі Robots.txt і через метатег robots.Еслі неякісний документ закритий від сканування в файлі Robots.txt і від індексування через метатег robots – сторінка ніколи не випаде з індексу, оскільки робот пошукової системи Google не побачить noindex, адже не може її просканувати.
- Використання кириличних символів. Варто завжди пам’ятати, що кирилиця не розпізнає пошуковими системами в файлі Robots.txt, обов’язково потрібно замінити на punycode. Посилання на конвертер.

Довідкові матеріали
Коли-небудь настане день і знамення олдові «Термінатора» стануть реальністю – роботи заполонять світ і візьмуть верх над людством. І тільки вправні знавці машин зможуть лавірувати в смертельній сутичці. Як добре ви вмієте спілкуватися з роботами? Чи зможете очолити повстання проти машин? Давайте перевіримо!