Атрибут rel = “canonical” як спосіб боротьби з дублікатами
 Унікальність і якість контенту на сторінці — фактори, що впливають на ранжирування сайту. Дублікати сторінок усередині сайту завдають шкоди його пошуковому просуванню. Як наслідок — сайт гірше ранжирується в органічному пошуку.
Унікальність і якість контенту на сторінці — фактори, що впливають на ранжирування сайту. Дублікати сторінок усередині сайту завдають шкоди його пошуковому просуванню. Як наслідок — сайт гірше ранжирується в органічному пошуку.
1. Які сторінки вважаються канонічними, а які — дублями?
Якщо на вашому сайті одна і та ж сторінка доступна за кількома URL, або різні сторінки містять схожий контент (наприклад, версії для мобільних пристроїв і комп’ютерів), Google буде вважати один з цих URL канонічним, а решта — його дублікатами. Сканування канонічного URL буде виконуватися набагато частіше, ніж його копій, тому дуже важливо переконатися, що Google визначив канонічними саме ті сторінки, які такими й є.
Атрибут rel=”canonical” усуває дублі, «склеюючи» копіюючі один одного сторінки й, таким чином, дозволяє поліпшити ранжування сайту. Але на відміну від 301 редіректу (Moved Permanently), який перенаправляє користувачів на потрібну сторінку, атрибут rel = “canonical” призначений тільки для роботів. На взаємодії користувачів з сайтом це ніяк не позначається.
2. Як Google визначає канонічні сторінки?
Канонічним називають URL сторінки, яку роботи Google вважають головною серед кількох її варіантів на вашому сайті.
Канонічні сторінки вибираються за рядом критеріїв (сигналів). Ними можуть бути:
- протокол (http чи https);
- кращий для користувача домен;
- якість сторінки;
- присутність URL у файлі Sitemap;
- наявність маркера rel = “canonical”.
Варто відзначити, що навіть якщо ви повідомите Google про свій вибір, система як канонічна може вибрати іншу сторінку на власний розсуд.
Канонічний атрибут використовується в наступних випадках:
- необхідно зберегти сторінки з частково дубльованим контентом;
- виникають складнощі під час видалення або запобігання появи дублів;
- складно реалізувати 301 редирект;
- на сайті автоматично створюються версії сторінок для друку;
- на сайті містяться сторінки фільтрації.
3. Як можна вказати канонічну сторінку?
Детально про те, як вказати канонічну сторінку, можна прочитати в довідці Search Console.
Щоб задати атрибут rel=”canonical”, потрібно розмістити його в блоці сторінки, прописавши тег виду:
де https://example.com/a — адреса канонічної сторінки. Вказуючи URL канонічної сторінки, важливо ставити абсолютне посилання (повну адресу, включаючи http: // або https: //). Це знизить ризик появи помилок в HTTP.
Існують наступні нюанси:
- Тег rel=”canonical” → працює тільки для HTML-сторінок.
- HTTP-заголовок rel =”canonical” → працює для всіх типів сторінок.
- Файл Sitemap → менш значущий сигнал для робота Googlebot, ніж атрибут rel = “canonical”.
3.1. Коли rel = “canonical» не склеює сторінки
- Склеювання http і https версій сайту (в таких ситуаціях потрібно проставляти посторінковий редирект).
- Склеювання сторінок з www і без (в таких ситуаціях потрібно проставляти посторінковий редирект).
- Коли контент сторінок значно відрізняється. У такому випадку Google не буде слідувати рекомендації, зазначеній в тезі rel = “canonical”.
3.2. Коли rel=”canonical” склеює сторінки
Тег rel=”canonical” склеює сторінки тільки в тому випадку, коли канонічна сторінка, вибрана Google і користувачем збігаються. Для цього контент даних сторінок повинен бути максимально ідентичний.
Розглянемо основні випадки, коли rel=”canonical” успішно склеює сторінки.
3.2.1.Один товар за різними URL-адресами
Якщо сторінка з максимально ідентичним контентом доступна за двома URL, один з яких був обраний в якості канонічного.
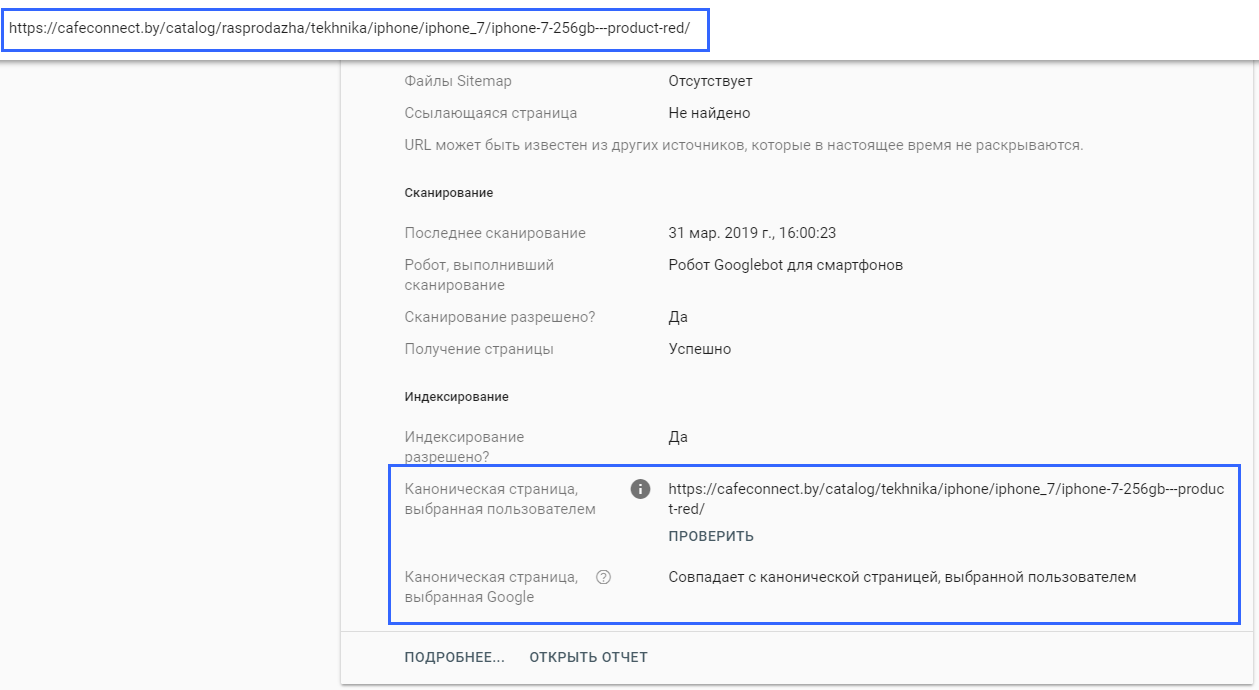
Приклад:
Зі сторінки https://cafeconnect.by/catalog/rasprodazha/tekhnika/iphone/iphone_7/iphone-7-256gb—product-red/ прописаний rel=”canonical” на дуже схожу сторінку https://cafeconnect.by/ catalog/tekhnika/iphone/iphone_7/iphone-7-256gb—product-red/
Таким чином ми склеюємо товар, який знаходиться в категорії «Розпродаж» з основною сторінкою даного товару.
3.2.2. Сторінки з get-параметрами, які не впливають на зміст документа
Залежно від CMS-системи сайту створюються різні сторінки з get-параметрами, наприклад, зазначенням мовної версії.
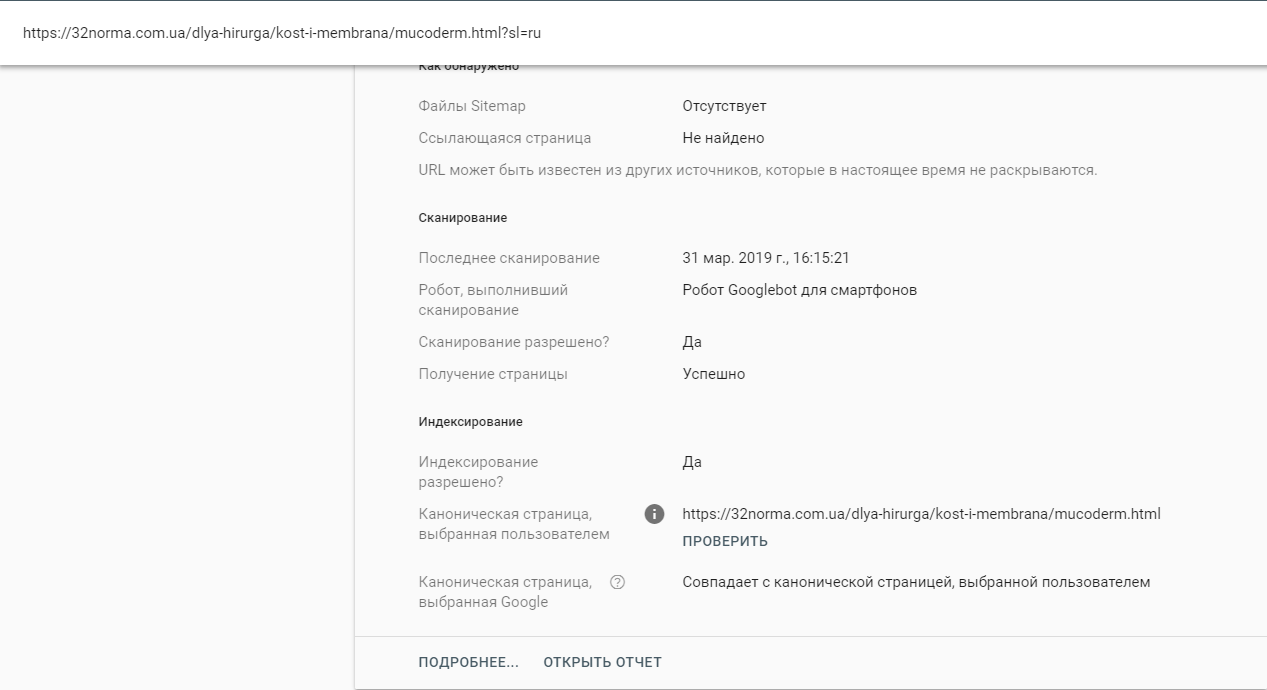
Приклад:
Зі сторінки https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html?sl=ru прописаний тег rel = “canonical” на сторінку https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html
Оскільки ці сторінки відрізняються лише наявністю get-параметрів, їх можна успішно склеїти.
Варто відзначити, що на практиці дії ПС не завжди відповідають нашим очікуванням. Навіть якщо ви вкажете одну канонічну сторінку, Google може вибрати в якості такої іншу. Це залежить від багатьох факторів, наприклад, від представлених на сторінці матеріалів або її ефективності в Google. Чіткого переліку причин, що впливають на вибір системи, не існує, а висновки фахівців будуються тільки на досвіді, логіці та здогадах.
4. Канонічний URL на іншому домені
Домен канонічної сторінки може відрізнятися від домену дубліката.
Довідка Google
У разі низької унікальності, ПС може сприймати сторінку дублем сторінки стороннього ресурсу.
Приклад з недавньої практики:
Ми поміняли домен, видаливши сайт на старому домені, але навіть після закінчення півтора місяці Google вважає сторінки нового сайту дублікатами старого.
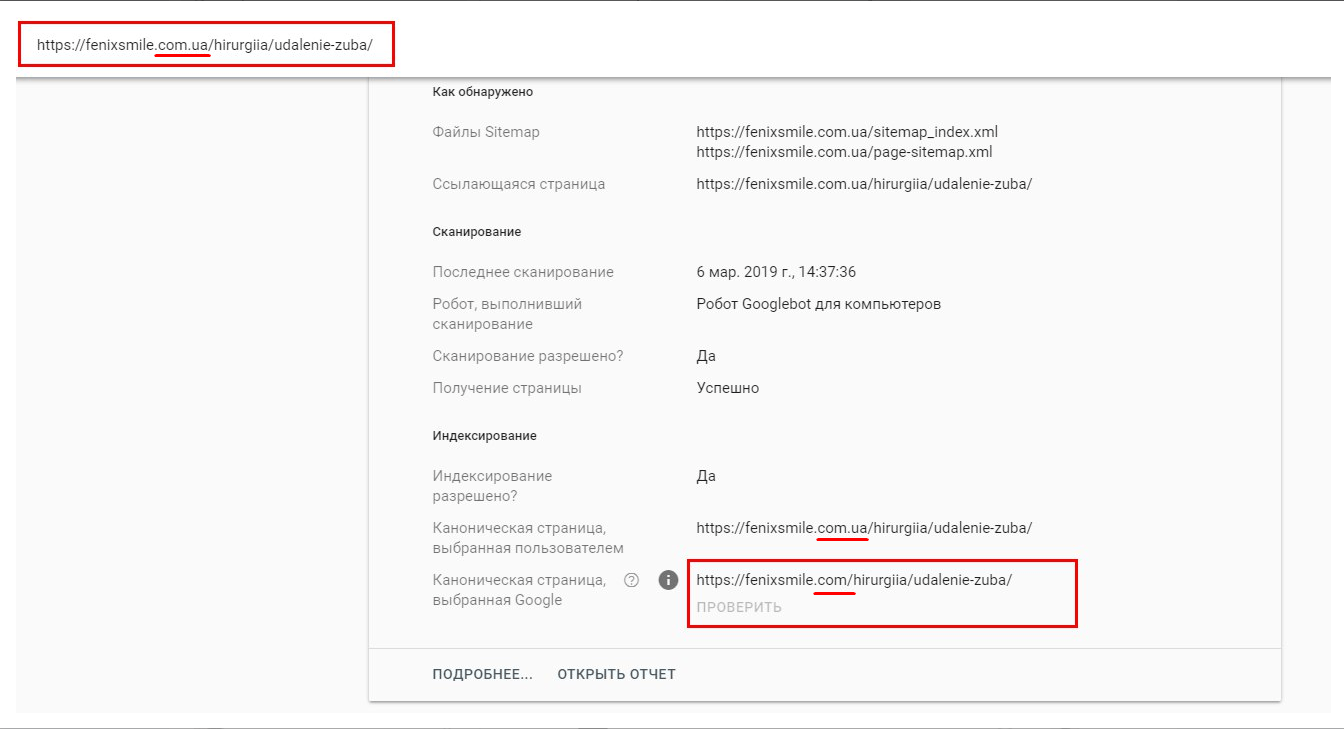
У Search Console вказано домен канонічної сторінки, оскільки в аккаунт додані обидва сайти. В інших ситуаціях відзначається, що «дана сторінка не належить до ваших ресурсів».
Що робити?
Переписувати контент на сторінці, максимально підвищувати рівень його унікальності та сподіватися на краще.
5. Як знайти канонічні помилки в Netpeak Spider
Переконатися, що rel = “canonical” виставлено коректно і веде на сторінку з 200 кодом відповіді сервера, можна за допомогою Netpeak Spider. Краулер визначає кілька типів канонічних помилок:
- canonical, заблокований в Robots.txt;
- ланцюжок canonical;
- дублікати canonical URL.
Пошук помилок проводиться в такому порядку:
- Запустіть Netpeak Spider.
- Відкрийте налаштування програми та перейдіть на вкладку «Параметри» на бічній панелі.
- Перевірте, відзначені чи параметри «Canonical» і «Канонічний URL» в пункті «Індексація».

- Вставте в рядок пошуку аналізований домен і натисніть кнопку «Старт», щоб почати інсталяцію.
- За підсумком сканування ознайомтеся з усіма знайденими помилками на вкладці бічній панелі «Звіти» → «Помилки».
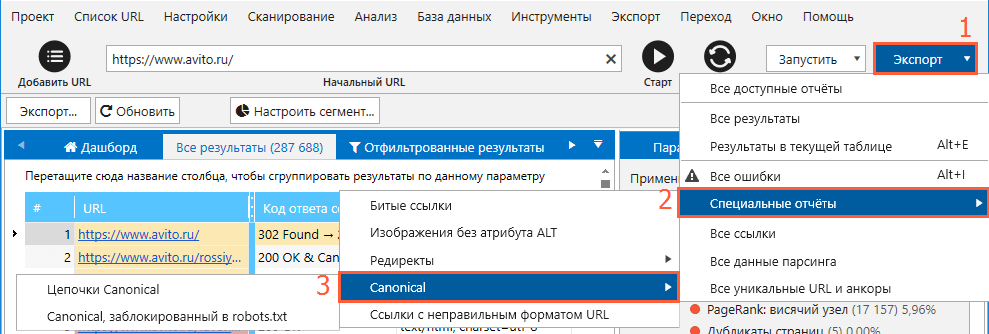
- Скористайтеся опцією «Експорт» → «Результати в поточній таблиці», щоб вивантажити відфільтровані результати з кожною окремою помилкою для передачі даних розробнику.
- За необхідності експортуйте всі дані, пов’язані з тегом сanonical, в окремий файл. Для цього натисніть в правому верхньому куті вікна кнопку «Експорт» → «Спеціальні звіти» → «Canonical».
6. Підіб’ємо підсумки
Атрибут rel=”canonical” — практично найдієвіший інструмент у процесі вказівки канонічних сторінок. Але навіть він сприймається пошуковою системою як рекомендація і не завжди впливає на вибір Google.
Необхідно переконатися в тому, що:
- ви правильно розмістили rel = “canonical”,
- унікальність сторінки відповідає необхідному рівню,
- всі значущі сторінки сайту доступні для індексації.
Корисні посилання на тему:
- Як консолідувати повторювані URL — довідка Search Console.
- Як запобігти скануванню однакових сторінок, URL яких розрізняються параметрами — довідка Search Console.
- Повторюваний контент — довідка Search Console.
![]()