Фішки Screaming Frog, про які не знає SEO-junior
 Стаття для досвідчених SEO-фахівців, які ведуть проекти самостійно та постійно користуються Screaming Frog. У ній – неочевидні засоби застосування інструменту. Custom Extraction, він же – парсинг через SF – хоч і входить до стандартного набору функціоналу, але не всі вміють ним користуватися. А мені здається, будь-якому SEO-фахівцеві буде корисно в цьому розібратися. Розповім про все поетапно та максимально зрозуміло.
Стаття для досвідчених SEO-фахівців, які ведуть проекти самостійно та постійно користуються Screaming Frog. У ній – неочевидні засоби застосування інструменту. Custom Extraction, він же – парсинг через SF – хоч і входить до стандартного набору функціоналу, але не всі вміють ним користуватися. А мені здається, будь-якому SEO-фахівцеві буде корисно в цьому розібратися. Розповім про все поетапно та максимально зрозуміло.
Найпопулярніші функції
Завдяки Screaming Frog, ми можемо виявити основні помилки на сайті:
- Сторінки з 301, 302, 307 редиректами.
- Сторінки з кодом відповіді 404.
- Вихідні посилання, які потрібно закрити в nofollow.
- Порожні, дубльовані, неоптимізовані метатеги TITLE, Description та заголовок H1.
- Сторінки з фрагментами, які необхідно закрити від індексації (?sort=, ?filter= та ін.).
Всі ви, цілком можливо, зустрічали в блогах різних компаній, які займаються просуванням в органічному пошуку, а також у публікаціях приватних сеошників. Загалом нічого нового. Тому йдемо далі.
Просунутий список помилок та перевірок
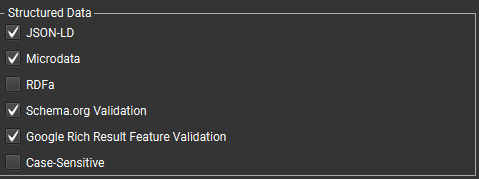
- Перевірка мікророзмітки, помилок та попереджень (вкладення Structure Data). Для цього в розділі Configuration-Spider поставте галочки:
- Перевірка індексування сторінок, проблеми зі сторінками, які вже в індексі та ін. Для цього важливо, щоб сайт був доданий до Search Console і підключити свій гугл аккаунт у «жабі» (так фахівці жартівливо називають Screaming Frog).
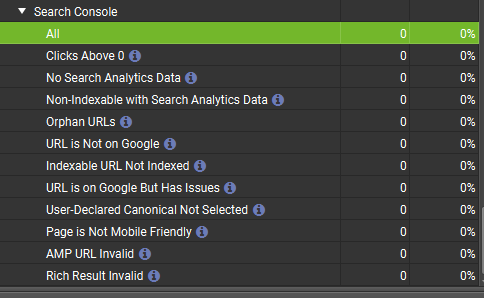
Тут нас цікавлять рядки:- URL is Not on Google – сторінка не в індексі.
- Indexable URL not Indexed – дозволена сторінка для індексації не в індексі.
- URL is on Google But Has Issues – сторінка в індексі, але має проблеми.
Це інформація, яка найдокладніше досліджується.
- Сканування з включеним JavaScript для динамічних сайтів:
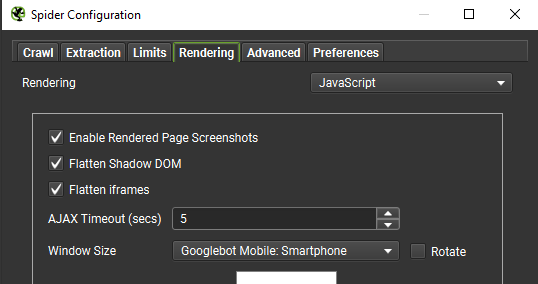
Особистого досвіду з такими сайтами у мене не було, але на прикладі американського сайту з пошуку зубного лікаря ми отримуємо всі сторінки:
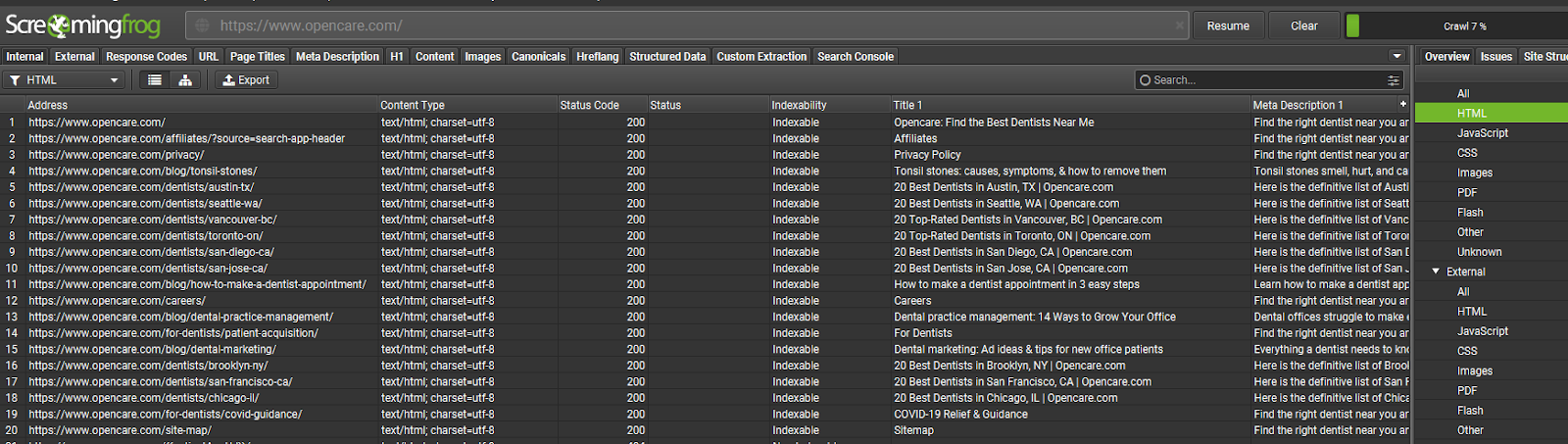
Парсим сайти за допомогою Screaming Frog на користь SEO
Що означає на користь SEO? Я маю на увазі, ведення певної статистики сайту, для зручного розуміння – на яких сторінках потрібно доопрацювати текст за обсягом, на які впровадити таблиці, блоки «Питання-відповідь» і т. д.
У моєму випадку це виглядає так:
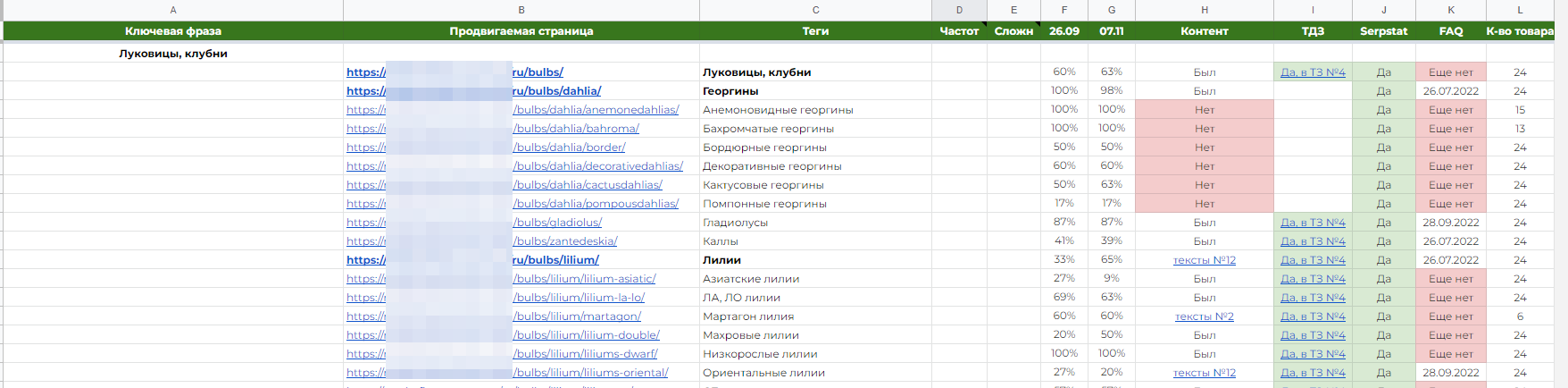
Коротко, я веду статистику за такими параметрами:
- наявність нового або старого контенту;
- наявність або відсутність блоку FAQ, і в якому він статусі (ні, впроваджено і дату події, чекаю на відповідь);
- кількість товару: тут я не підсумовував весь товар на сторінках пагінації, а брав лише першу з них. Як мінімум, у нас буде припущення, що погані позиції можуть бути через відсутність або малу кількість товару на сторінці.
А тепер повернемося до того, яким чином ми будемо отримувати ці дані.
Спочатку нам знадобиться будь-яке розширення для браузера, яке працює з XPATH. Наприклад, Toggle XPather. Він допоможе прямо на сайті бачити, чи правильно ми використовуємо шлях xpath для отримання потрібного елемента на сайті.
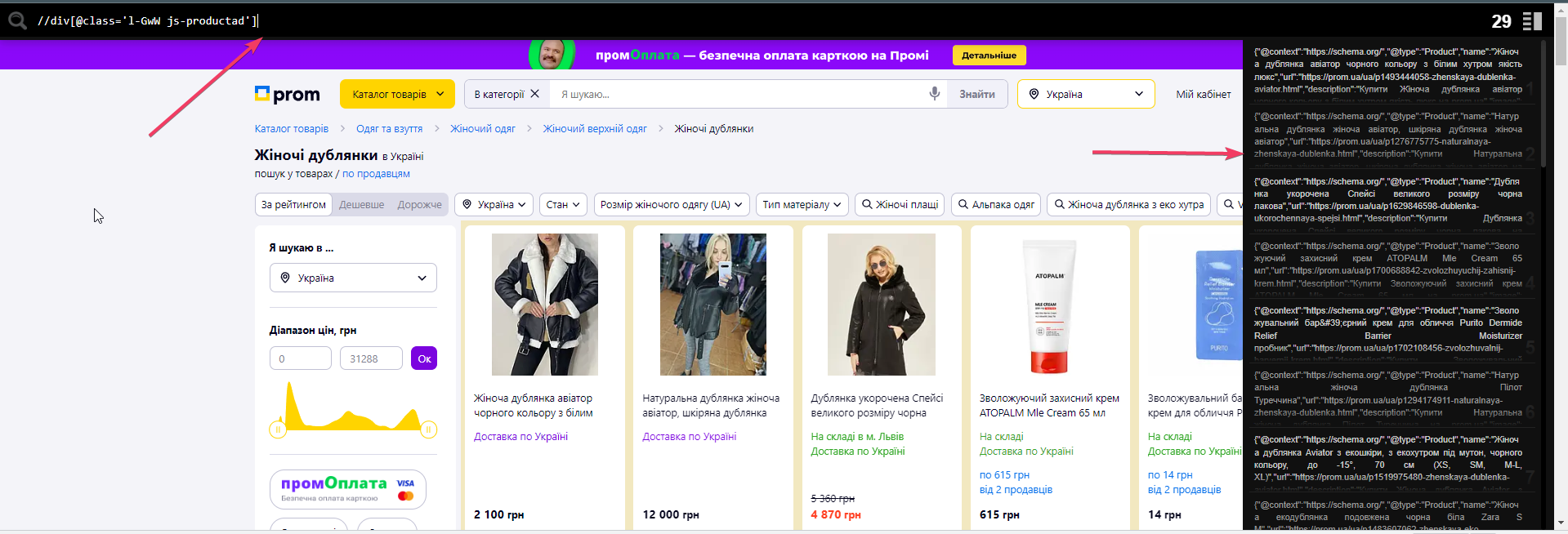
На зображенні видно, що при введенні коректного xpath (у нашому випадку – клас картки товару), розширення праворуч виводить те, що всередині цього тега та кількість таких тегів. Це візуально полегшує розуміння, що в результаті нам зможе витягнути Screaming Frog.
А тепер перейдемо до того, як розбивати дані, які є в моїй таблиці.
Бонусом я покажу додаткові варіанти, які можуть бути корисними.
Парсимо кількість товару на сторінці
Для цього нам потрібно взяти загальний class або ID для всіх карток товару. Це може бути як один з < div >, так і будь-який інший HTML-тег, який є тільки на картках і ніде більше.
Для прикладу візьмемо сайт Prom.ua
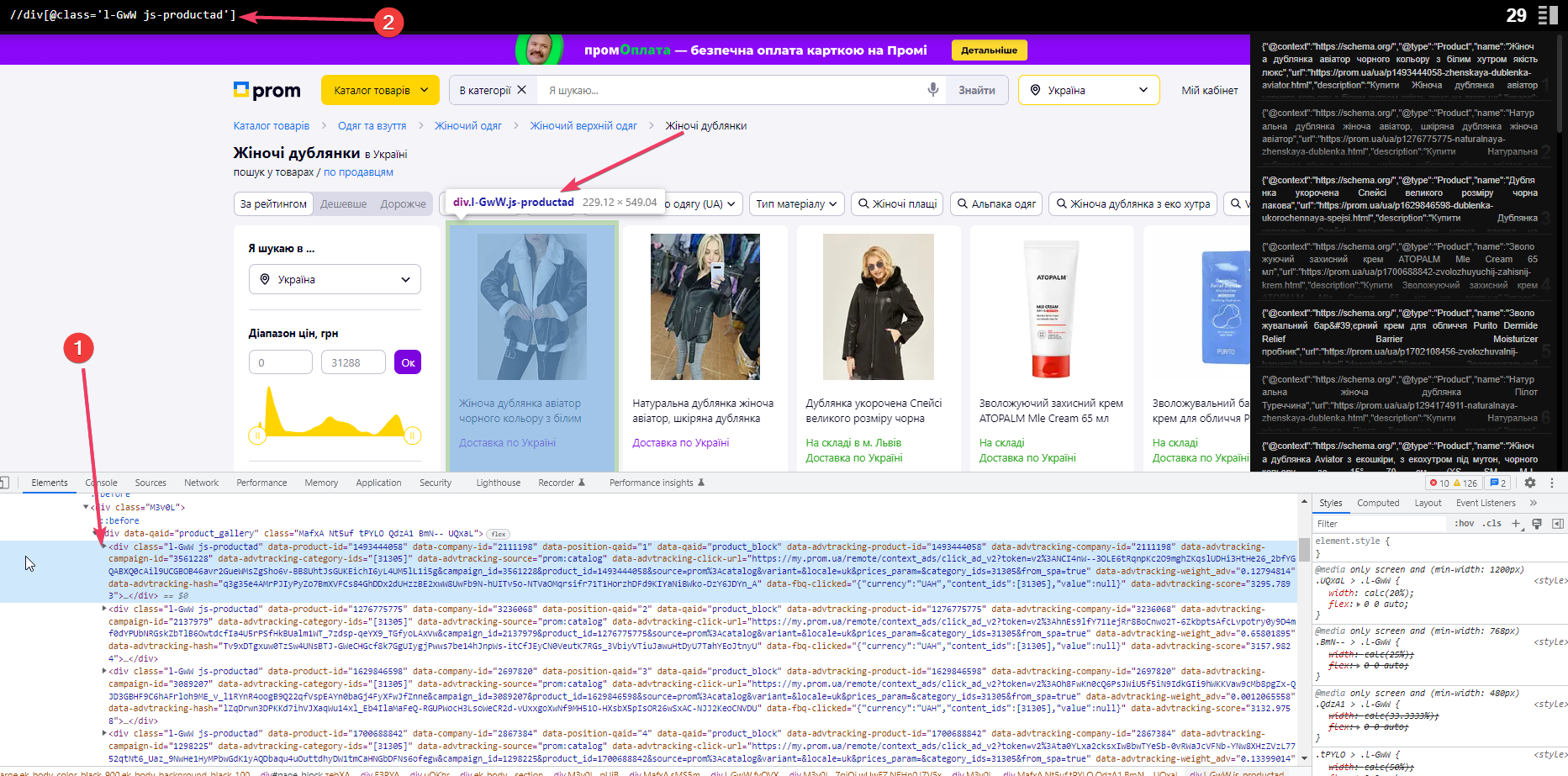
Всередині загального блоку < div data-qaid=”product_gallery” class=”MafxA Nt5uf tPYLO QdzA1 BmN– UQxaL” > є блок з класом l-GwW js-productad, який дублюється на кожній картці. Беремо його, вказуємо для початку розширення – //div[@class=’l-GwW js-productad’]. Підсвічується те, що треба, бачимо число 29 – це означає 29 блоків на сторінці.
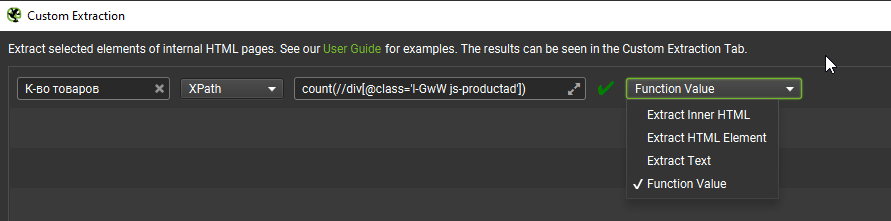
Щоб отримати тільки число, додаємо до формули count(//div[@class= ‘l-GwW js-productad’]) та у жабі виставляємо «Function Value».
Отримуємо результат:

Використовувати можна режим Spider або List
Парсимо кількість символів у тексті
Розглянемо на прикладі Barb.ua
Знаходимо блок та його клас, де знаходиться текст. Але підсвічується два замість одного. Значить, десь є такий самий блок.
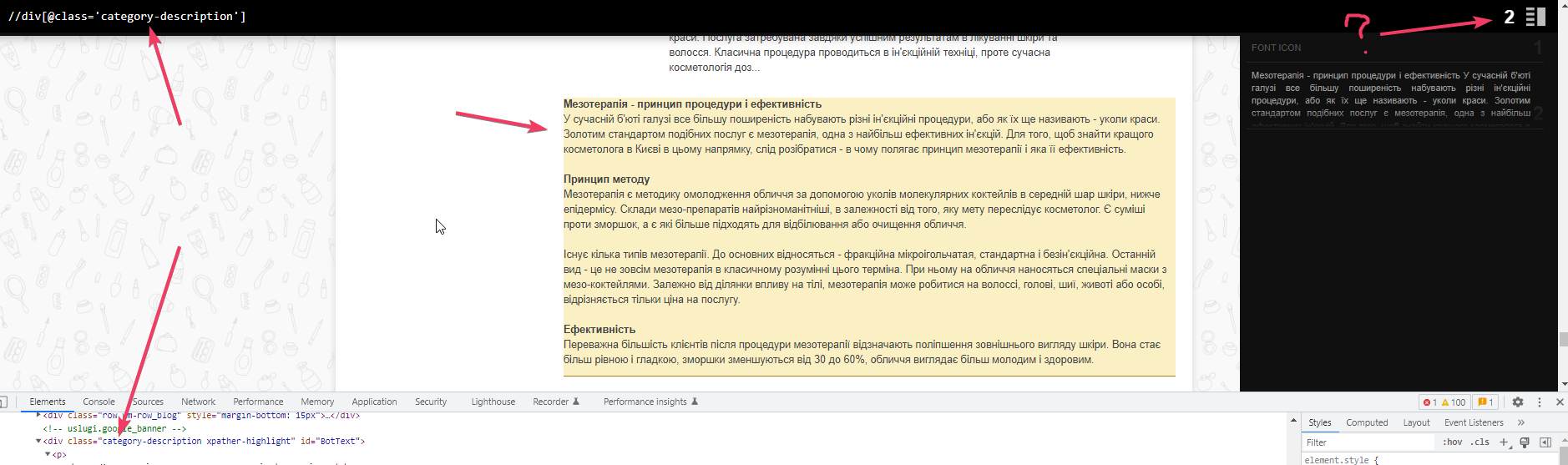
Так, ось він. Саме через нього просто спарсити не вийде, треба дати раду.
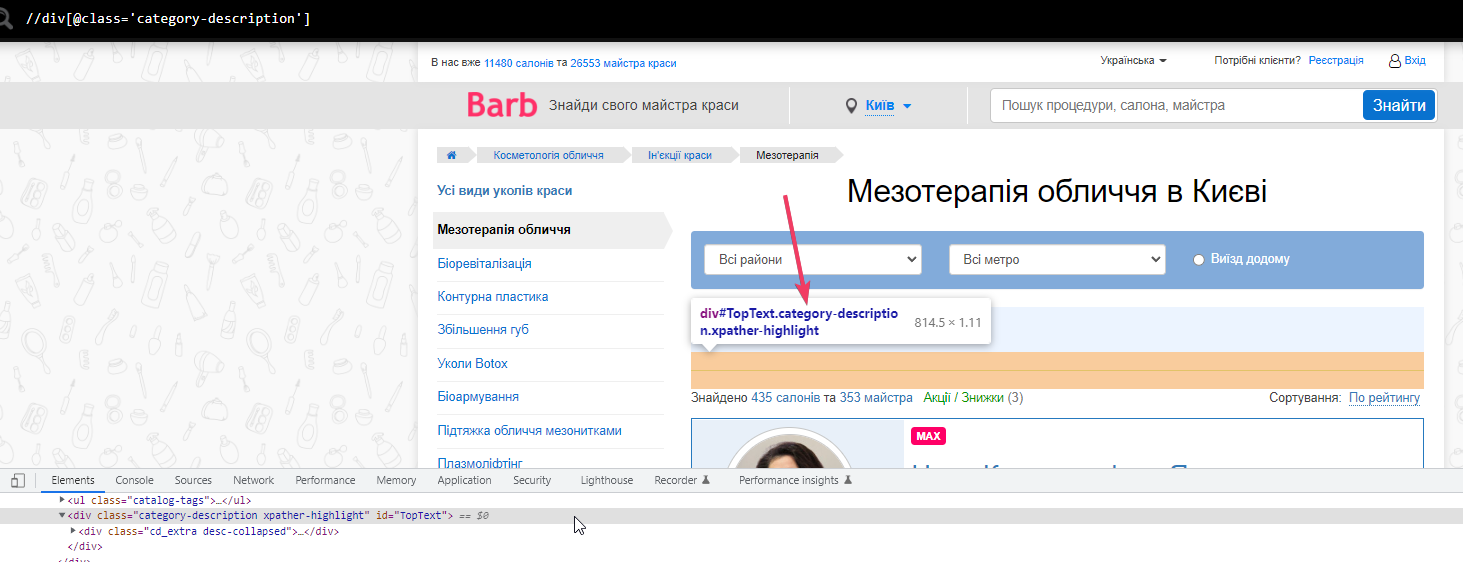
Тому намагаємося дістати через ID, він тут унікальний (як і 95% інших випадків).

Дістаємо текст через id=”TopText” але отримуємо довжину всього 244 символ. Хоча якщо перевірити, то тексту там на 1400 символів
Трохи уважності та знань xpath. Я знайшов два варіанти, які дадуть нам коректні дані. Ділюсь:
Варіант №1. string-length((//div[@class=’category-description’])[2]) – через клас, але з уточненням саме про другий блок. Зверніть увагу на конструкцію та на майбутнє запам’ятайте – точно знадобиться та спростить життя.
![На скрине я убрал функцию подсчета, чтобы просто визуально показать, что [2] работает](https://inweb.ua/blog/wp-content/uploads/2022/12/na-skrine-ya-ubral-funktsiyu-podscheta-chtoby-prosto-vizualno-pokazat-chto-2-rabotaet.png)
На скрині я прибрав функцію підрахунку, щоб просто візуально показати, що [2] працює
Варіант №2. string-length(//div[@id=’BotText’]/p) – оскільки в даному випадку після < div > весь текст знаходиться в < p >:

На скріншоті бачимо стару версію інтерфейсу в росмові
Якщо вам потрібен сам текст, а не його кількість символів, потрібно:
- У налаштуваннях Custom Extraction замінити «Function Value» на Extract Inner Html.
- З конструкції прибрати string-length.
І отримуємо розмічений тегами текст, який ви можете використати на свій розсуд:

А що б ще спарсити… ? Підкидаю кілька ідей
Блок з перелінковкою
Тут нам потрібен батьківський блок + звернення до дочірніх блоків + @href якщо потрібне лише посилання або просто //a – якщо потрібен текст посилання. Зверніть увагу, що у кожного сайту класи тегів є унікальними. Наприкінці статті я покажу кілька стандартних рішень.
//div[@class=’M3v0L Tr1FH C6zKA NR0J4 MuCm8′]//div[@class=’l-GwW’]//@href

Якщо потрібно просто дізнатися, є Чи такий блок та його кількість, повторюємо те саме, що і з товаром.
count(//div[@class=’M3v0L Tr1FH C6zKA NR0J4 MuCm8′])
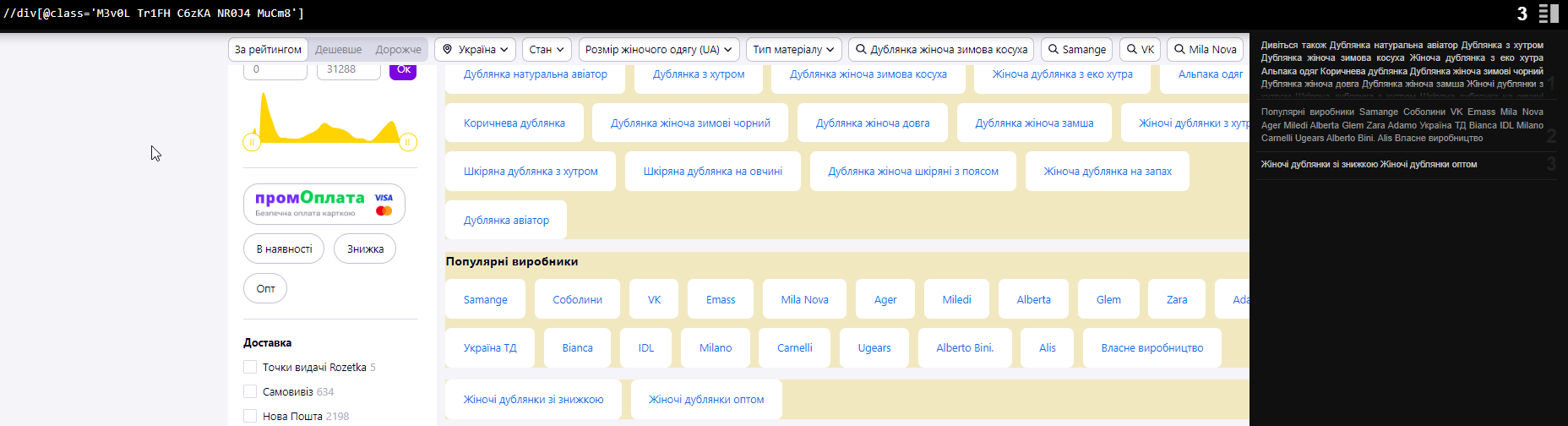
… і отримуємо кількість таких блоків
Вміст контенту для знаходження потрібного ключа\слова
Припустимо, вам потрібно спарсити певні імена фахівців або просто знайти слово, яке ви забули перекласти з російської українською мовою, десь у контенті. Тут приходить допомогу конструкція [contains(p, ‘word’)]. Де замість “p” ми вказуємо потрібний нам HTML-тег або ставимо просто “.” , щоб шукати в будь-яких тегах і замість word 00 шукане слово символ. Наприклад, треба знайти українські літери “і, ї, є”.
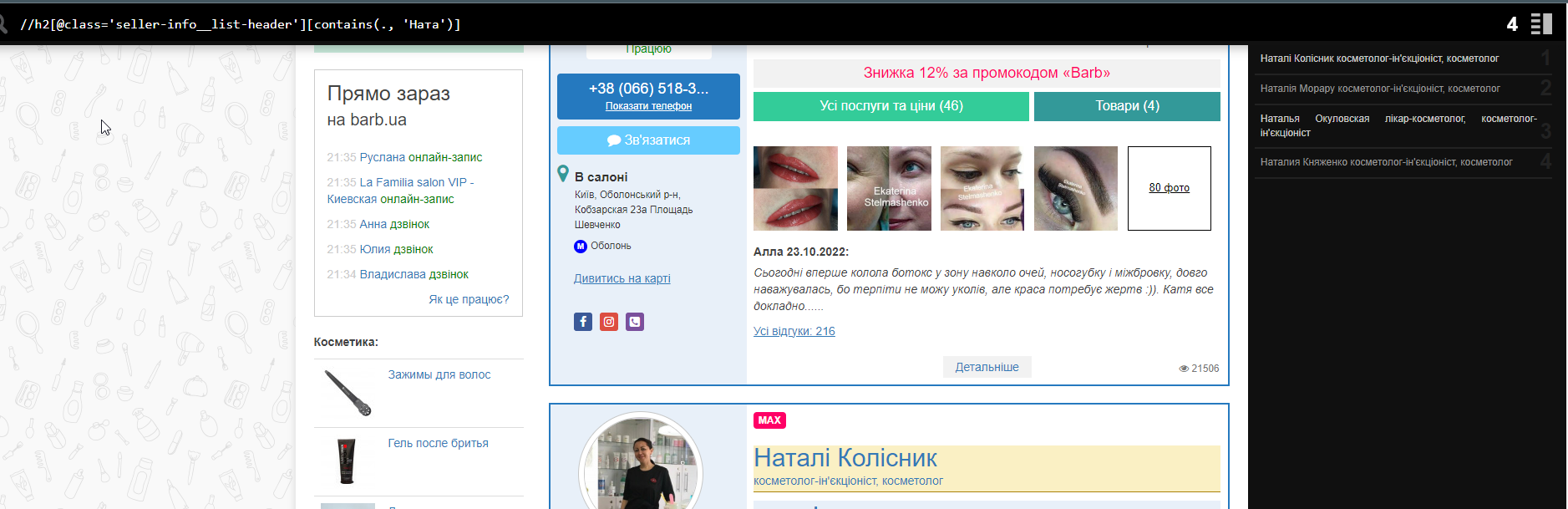
Можна так: //h2[contains(., ‘Натал’)] або //h2[@class=”seller-info__list-header”][contains(.,”Натал” )]
Дата кешу сторінки в Google
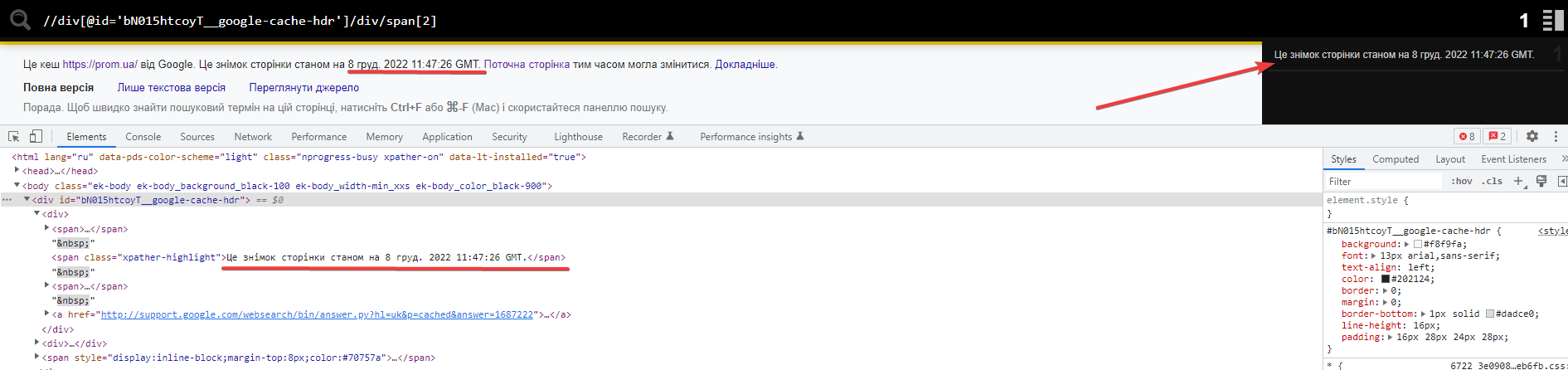
Для цього нам потрібний ID блоку < div > та другий за списком для отримання більш короткої пропозиції.
//div[@id=’bN015htcoyT__google-cache-hdr’]/div/span[2] – готова формула.
Беремо список потрібних нам сторінок, додаємо в Excel, зчіплюємо посилання з формулою http://webcache.googleusercontent.com/search?q=cache і відправляємо до Screaming Frog:

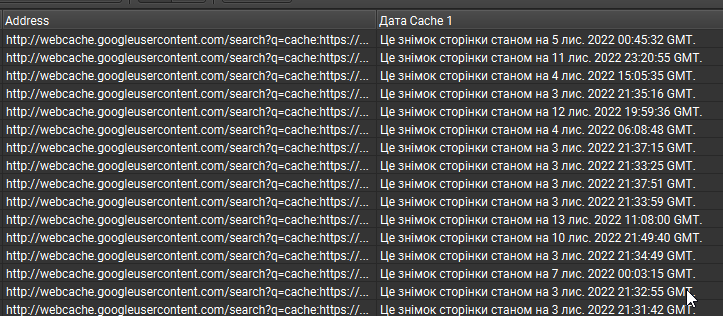
Важливо! Таку ж таблицю ми можемо отримати і з допомогою формул у Google Sheets. Проблема в тому, що там постійно у багатьох осередках показує НД. Якщо є варіанти, як можна цього уникнути для великої кількості сторінок, радий розглянути і, можливо, використовувати в майбутньому. Пишіть у коментарі, я обов’язково відповім.
Шпаргалки (як і обіцяв)
Таблички з готовими методами парсингу за допомогою Xpath та Regex (регулярні вирази).
Офіційний гайд з парсингу.
Висновок
Завдяки вмінням парсити сайти за допомогою відносно безкоштовної Screaming Frog, ми можемо діставати багато важливої інформації та використовувати її в різних цілях. Можемо:
- наповнити сайт чужим контентом, але ми знаємо, що це робити небажано:
- вести статистику за своїм чи клієнтським проектом;
- використовувати при знаходженні/додаванні фішок, які помітили у конкурента та багато чого іншого.
Вирішувати тільки вам.
І для тих, кому реально цікаво! Як можна вивантажити дату кеша ще коротше? Щоб тільки число та рік були? Варіанти залишайте у коментарях! Буде цікаво!