Полное руководство по использованию файла Robots.txt
Что такое Robots.txt?
Robots.txt — текстовый файл, в котором указываются правила сканирования сайта для поисковых систем. Файл находится в корневой папке и является обычным текстовым документом в формате .txt.
Поисковые системы сначала сканируют содержимое файла Robots.txt и только потом остальные страницы сайта. Если файл Robots.txt отсутствует — поисковым системам разрешено сканировать все страницы сайта.
Содержание
- Что такое Robots.txt?
- Для чего нужен файл Robots.txt
- Как создать текстовый файл Robots.txt
- Требования к файлу Robots.txt
- Ограничения документа Robots.txt
- Обозначения и виды директив
- В каком порядке выполняются правила
- Примеры использования файла Robots.txt
- Наиболее распространенные ошибки
- Справочные материалы
Для чего нужен файл Robots.txt
- Указать поисковым системам правила сканирования и индексации страниц сайта. Для каждого поисковика можно задать как разные правила, так и одинаковые.
- Указать поисковым системам ссылку на xml-карту сайта, чтобы роботы могли без проблем её найти и просканировать.
Основной задачей robots.txt является управление доступа к страницам сайта поисковым системам и другим роботам. На сайте может находиться конфиденциальная информация, например, личные данные пользователей или внутренние документы компании. Благодаря директивам в файле Robots.txt можно запретить к ним доступ поисковым системам и их не найдут.
Для Google содержимое файла является рекомендацией по сканированию сайта. Если страница закрыта в файле Robots.txt, она все равно может попасть в индекс поисковой системы Google, ведь для него это рекомендации по сканированию, а не индексации.
Чтобы не допустить индексации определенных страниц сайта нужно использовать метатег robots или X-Robots-Tag.
Как создать текстовый файл Robots.txt
- Создайте текстовый документ в формате .txt.
- Задайте ему имя robots.txt.
- Укажите содержимое файла.
- Добавьте его в корневой каталог сайта, чтобы он был доступен по адресу /robots.txt.
- Проверьте корректность файла через инструмент Google.
Файл Robots.txt должен обязательно находиться по адресу robots.txt. Если он будет размещен по другому url-адресу, поисковая система будет его игнорировать и считать, что всё разрешено для сканирования и индексации.

Правильно:
https://inweb.ua/robots.txt
Неправильно:
https://inweb.ua/robots.txt
https://inweb.ua/ua/robots.txt
https://inweb.ua/robot.txt
Для популярных CMS есть плагины для редактирования файла Robots.txt:
- WordPress — Clearfy Pro.
- Opencart — редактор Robots.txt.
При помощи указанных модулей можно легко изменять директивы через административную панель, без использования ftp.
Требования к файлу Robots.txt
Чтобы поисковые системы обнаружили и следовали директивам необходимо следовать следующим правилам:
- Размер файла не превышает 500кб;
- Это TXT-файл с названием robots — robots.txt;
- Файл размещен в корневом каталоге сайта;
- Файл доступен для роботов — код ответа сервера – 200.
- Если файл не соответствует требованиям – сайт считается открытым для сканирования и индексации.
Если же поисковая система, при запросе файла /robots.txt, получила код ответа сервера отличный от 200 – сканирование сайта прекратится. Это может существенно ухудшить скорость сканирования сайта.
Ограничения документа Robots.txt
- Не все поисковые системы обрабатывают директивы в файле Robots.txt одинаково. У каждой есть своя интерпретация. При составлении правил следует на это обращать внимание.
- Каждая директива должна начинаться с новой строки.
- У каждой поисковой системы есть несколько роботов, которые сканируют сайты. Некоторые из них интерпретируют правила robots.txt иначе.
- В файле Robots.txt разрешается использовать только латинские буквы. Если у вас кириллические url-адреса или домен – необходимо использовать punycode.
Рассмотрим на примере, как Robots.txt использует кодировку:
Неправильно:
User-agent: *
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
Правильно:
User-agent: *
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap:http://xn--80aswg.xn--p1ai/sitemap.xml
Обозначения и виды директив
Ниже рассмотрим какие есть директивы в файле Robots.txt
- User-agent — указание поискового бота, к которому применяются правила. Чтобы выбрать всех роботов – укажите “*”. Директива обязательна для использования, без указания User-gent нельзя использовать какие-либо правила.Например:User-agent: * #правила для всех.
User-agent: Googlebot #правила только для Google.
User-agent: Yandex #правила только для Яндекса. - Disallow — директива, которая запрещает сканирование определенных страниц или разделов.Например:Disallow: /order/ #закрывает все страницы, которые начинаются с /order/.
Disallow: /*sort-order #закрывает все страницы, которые содержат фрагмент “sort-order”.
Disallow: /secretiki/ #закрывает все страницы, которые начинаются с /secretiki/. - Sitemap — указание ссылки на xml-карту сайта. Если xml-карт сайта несколько – можно указать их все.Например:Sitemap: https://inweb.ua/sitemap.xml
Sitemap: https://inweb.ua/sitemap-images.xml - Allow — позволяет открыть для робота страницу или группу страниц.Например:Disallow: /category/
Allow: /category/phones/
Мы закрываем все страницы, которые начинаются с /category/, но открываем /category/phones/ - Спецсимволы:* – обозначает любое кол-во символов.Например:Disallow: * #запрещает сканирование всего сайта.
Disallow: *limit #Запрещает сканирование всех страниц, которые содержат “limit”.
Disallow: /order/*/success/ #запрещает сканирование всех страниц, которые начинаются с /order/, потом содержат любое кол-во символов, а потом /success/. - $ – обозначает конец строки.Например:Disallow: /*order$ #запрещает сканирование всех страниц, которые заканчиваются на order.
В каком порядке выполняются правила
Google обрабатывает директивы Allow и Disallow не по порядку, в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
Будет прочитана как:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило “Disallow: /wp-” ссылку запретит, а следующее правило “Allow: */uploads” её разрешит и ссылка будет доступна для сканирования.
В случае, если директивы равнозначны или противоречат друг-другу:
User-agent: *
Disallow: /admin
Allow: /admin
Приоритет отдается директиве Allow.
Примеры использования файла Robots.txt
1. Закрываем полностью сайт от индексации:
User-agent: *
Disallow: /
2. Блокируем доступ к папке для Google, остальным поисковым системам открываем.
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /papka/
3. Cайт полностью открыт для индексации.
User-agent: *
Disallow:
4. Закрываем все страницы сайта, которые содержат фрагмент url-адреса “secret”.
User-agent: *
Disallow: /*secret
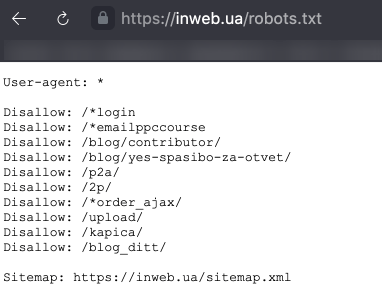
5. Пример файла Robots.txt с указанием директивы Sitemap:
User-agent: *
Disallow: /*login
Disallow: /*emailppccourse
Disallow: /p2a/
Disallow: /2p/
Sitemap: https://inweb.ua/sitemap.xml
7. Пример комментирования строк в файле Robots.txt:
User-agent: *
#allow: /*?q=*
#allow: /watermark.php*
#Allow: /*.js*
#Allow: /*.css*
#Allow: /*.png*
#Allow: /*.jpg*
#Allow: /*.gif*
Disallow: /*?filter=*
Disallow: /*?sticker=*
Disallow: /*?brands=*
Disallow: /*?country=*
8. Закрываем от сканирования все страницы сайта, которые заканчиваются на .html
User-agent: *
Disallow: /*.html$
Наиболее распространенные ошибки
Рассмотрим наиболее распространенные ошибки, которые допускают SEO-специалисты при составлении директив.
- Отсутствие в самом начале директивы звездочки. Стоит помнить, что обязательно нужно добавлять * перед фрагментом url-адреса, если директива содержит фрагмент, который находится не в начале url-адреса.
Например, нужно закрыть от сканирования url-адрес https://inweb.ua/catalog/cateogory/?sort=name
Неправильно: Disallow: ?sort=
Правильно: Disallow: /*sort= - Директива, помимо некачественных url-адресов, запрещает сканирование качественных страниц. При написании директив стоит указывать их максимально четко, чтобы даже теоретически качественные url-адреса не попали под запрет.
Неправильно: Disallow: *sort
Правильно: Disallow: /*?sort=
В первом случае, случайно могут быть страницы вида: https://inweb.ua/kak-zakryt-ot-indeksacii-sortirovki/ Ведь, теоретически, некоторые страницы могут содержать в url-адресе фрагмент “sort”. - Страницы одновременно закрыты в файле Robots.txt и через метатег robots. Если некачественный документ закрыт от сканирования в файле Robots.txt и от индексирования через метатег robots – страница никогда не выпадет из индекса, так как робот поисковой системы Google не увидит noindex, ведь не может её просканировать.
- Использование кириллических символов. Стоит всегда помнить, что кириллица не распознается поисковыми системами в файле Robots.txt, обязательно нужно заменить на punycode. Ссылка на конвертер.