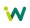Оптимизация фильтров в интернет-магазине
Интернет-магазин не может обойтись без фильтров. Их видно слева, сверху, реже справа на странице. Если клиент знает чего хочет, фильтрация помогает быстро выбрать товар с нужными характеристиками.
Содержание статьи
Пример фильтров на сайте интернет-магазина:
Фильтрация — это возможность выбрать нужную линейку товаров благодаря подобранным параметрам и характеристикам. Параметры фильтров чаще всего можно увидеть на страницах интернет-магазинов. Фильтрация помогает охватить трафик под среднечастотные (далее по тексту СЧ, прим.ред.) и низкочастотные (далее по тексту НЧ, прим.ред.) запросы, которые занимают немалую долю семантического ядра сайта.Преимущества СЧ и НЧ запросов:
- более низкая конкуренция;
- по ним проще продвигаться в интернете;
- они более конверсионные чем высокочастотные (далее по тексту ВЧ, прим.ред.). Опыт работы с проектами показывает, что пользователи, ищущие товар по СЧ и НЧ запросам, настроены на покупку больше чем пользователи, которые ищут по ВЧ запросам.
Оптимизация страницы фильтра или создание отдельной посадочной страницы: что выбрать?
При создании структуры страниц сайта следует учитывать, что категории и подкатегории продвигать легче, чем страницы фильтров. Это объясняется тем, что страницы категорий и подкатегорий лучше ранжируются. У таких страниц внутренний PR выше (внутренний вес страницы,прим.ред.), так как они находятся в меню сайта.
Страницы фильтров индексироваться могут хуже и PR у них будет ниже, так как на них ссылается меньшее количество страниц или даже всего одна ссылка из категории с фильтром. Мы рекомендуем иметь на сайте категории и подкатегории для популярных разделов, которые потенциально интересны клиентам и могут приносить много трафика.
Зачем нужна оптимизиция фильтров?
Страницы фильтров имеют ряд преимуществ:
- рост позиций в выдаче по запросам низкой и средней частотности;
- увеличение видимости сайта;
- рост органического трафика за счет СЧ и НЧ запросов;
- улучшение поведенческих факторов благодаря удобству использования сайта;
- увеличение конверсий и уменьшение показателя отказов: пользователи, которые вводят целевой запрос, чаще всего знают, какой товар они хотят приобрести.
Правильная оптимизация страниц фильтров позволит сделать их одними из трафикогенерирующих страниц всего сайта. В этой статье я расскажу как сделать это.
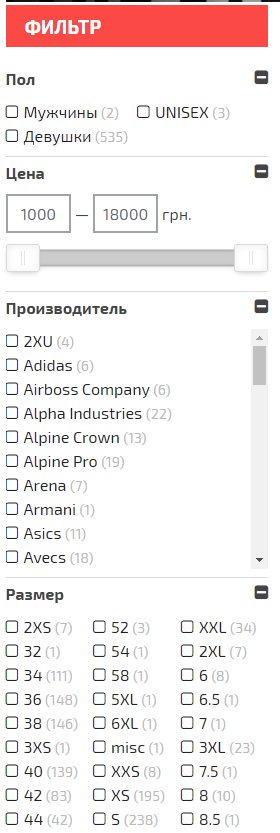
Пример фильтров на сайте, где они одни из самых трафиковых:
Оптимизация страниц фильтров поможет в продвижении интернет-магазинам — клиенты будут покупать быстрее и охотнее. Находясь на сайте, они смогут найти нужный товар с помощью предложенных параметров, а также попасть сразу на страницу фильтрации из поиска, используя СЧ и НЧ запросы.
Какие бывают системы фильтрации
Использование AJAX
Как работает: при выборе необходимых параметров фильтр формируется без перезагрузки страницы. В отдельных случаях можно увидеть добавление # к основному URL страницы, что тоже, по сути, не меняет саму страницу.
Такие документы не попадают в индекс и не приносят дополнительный органический трафик.

Плюсы данного метода:
- нет дублей страниц в индексе;
- краулинговый бюджет не тратится на обход бесполезных, дублирующихся страниц.
Минусы:
- отсутствуют страницы фильтров, соответственно нет дополнительного трафика на сайт.
Наличие GET-параметра в URL
Как работает: формируются дополнительные страницы с добавлением GET-параметра, который начинается с символа «?».
Этот метод более удобный, чем первый. Но тут могут возникнуть нюансы: наличие дублей и генерация мусорных страниц в индексе.
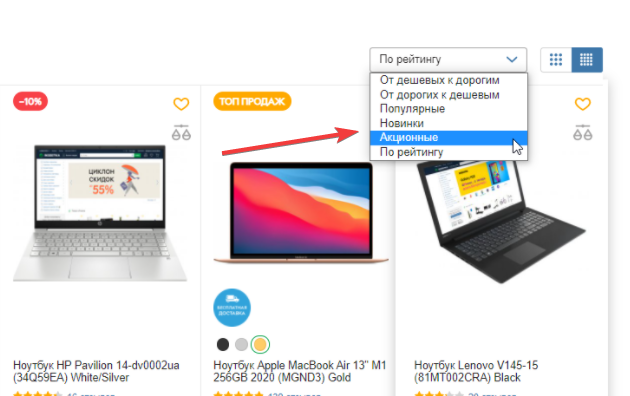
Кроме страниц фильтров существуют общие страницы фильтрации, где используют UTM-метки:
- диапазон цен;
- новые товары;
- товары по акции и распродажи;
- страницы сортировок по цене, алфавиту, популярности.

Плюсы метода:
- формирование новых страниц, которые принесут трафик на сайт.
Минусы:
- образование огромного количества мусорных страниц в индексе;
- «пустое» расходование краулингового бюджета сайта;
- низкая релевантность ключевым словам по большей части страниц.
Статические URL
Здесь разделим понятие на две категории: статический URL и статический человекопонятный URL (далее ЧПУ URL).
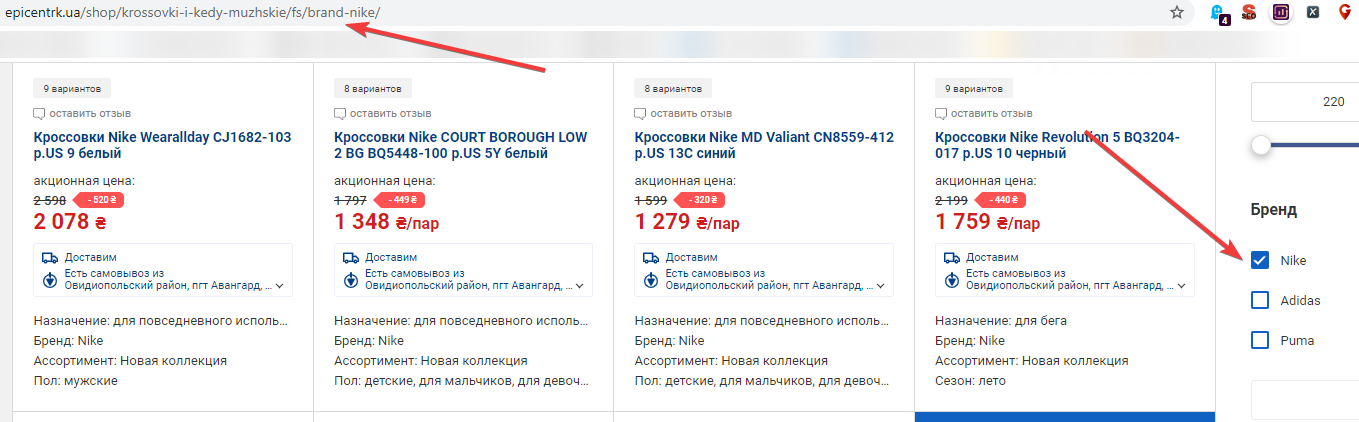
Статический URL подразумевает использование цифр и букв с разделителями. Например, https://site.com/notebooks/c80004/apple/.
Статический человекопонятный URL — самый оптимальный для поисковой оптимизации. В данном случае в URL используется транслит для страниц фильтров.
Формирование ЧПУ URL помогает поисковым системам понять о чем страница и будет ли этот URL релевантен поисковому запросу.
С такими страницами легко работать при наращивании ссылочной массы и при перелинковке страниц.
Плюсы:
- понятны поисковым системам;
- наличие новых посадочных страниц;
- маловероятно появление дублей страниц;
- высокий CTR (отношение кликов к показам, измеряется в %) в сравнении со статическими страницами и страницами с GET-параметрами;
- можно оптимизировать, указать метаданные, заголовок h1 и добавить тексты.
Минусы:
- не на всех сайтах можно реализовать.
Как организовать систему фильтрации интернет-магазина
Лучшим вариантом является организация ЧПУ URL для страниц фильтров уже на этапе разработки сайта.
Какие задачи следует решить для страниц фильтрации:
- Сформировать ЧПУ URL, для страниц первого уровня и пересечения нескольких фильтров.Организовать перелинковки страниц фильтрации.
- Настроить генерации метаданных и заголовка h1.
- Добавить дополнительный функционал добавления текстов на сайт.
Открытие страниц к индексации
Оставлять все страницы фильтрации в индексе не имеет смысла, нужно открыть только те, которые смогут принести пользу продвижению: страницы фильтров первого уровня и пересечения двух фильтров.
Пересечения трех и более фильтров используют реже или совсем закрывают к индексации. Здесь нужно учитывать наличие ключевых фраз для данных страниц.
Не забываем закрывать от индексации страницы сортировок (по цене, популярности и прочее). Страницы с выбором двух параметров одного фильтра, например «Бренд» + «Бренд», также рекомендуем закрывать к индексации.
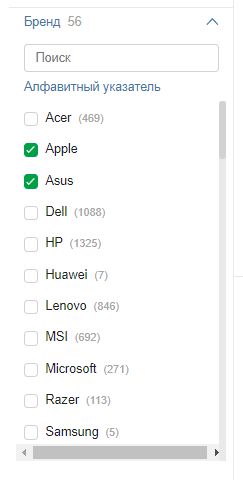
Формирование URL для страниц фильтров
Здесь важно соблюдать вложенность URL при выборе нескольких фильтров, независимо от последовательности выбора параметров.
Несоблюдение данного правила создаст огромное количество дублей страниц.
Неправильно:
Пример 1: выбираем параметр №1, а потом параметр №2.
Пример 2: выбираем параметр №2, а потом параметр №1:
- site/filter1/filter2/;
- site/filter2/filter1/.
Правильно:
Пример 1: выбираем параметр №1, а потом параметр №2.
Пример 2: выбираем параметр №2, а потом параметр №1:
- site/filter1/filter2/;
- site/filter1/filter2/.
Формирование метаданных и добавление контента
Админпанель сайта должна позволять:
- генерацию шаблонных метаданных. Лучшим вариантом будет возможность «гибкого» внедрения шаблона (возможность склонять, менять местами параметры для метаданных и заголовка h1);
- добавление метаданных и заголовка h1 вручную;
- добавление контента на страницы фильтров.
Если в CMS отсутствует возможность оптимизации метаданных и контента на сайте, следует доработать функционал или приобрести необходимый модуль. Без таких функций работы по оптимизации страниц фильтров и управлению индексацией будут напрасными.
Перелинковка страниц фильтров
Для лучшей индексации страниц фильтров, которые могут приносить трафик, следует добавить перелинковку. Ссылки можно поставить:
- в файл sitemap.xml;
- в пользовательскую карту сайта;
- в тексте сделать перелинковку с других страниц;
- добавить облако тегов;
- добавить ссылки на страницы фильтров на странице категории;
- добавить трафикогенерирующие страницы фильтров в выпадающее меню сайта.
Примеры реализации страниц фильтров на сайтах
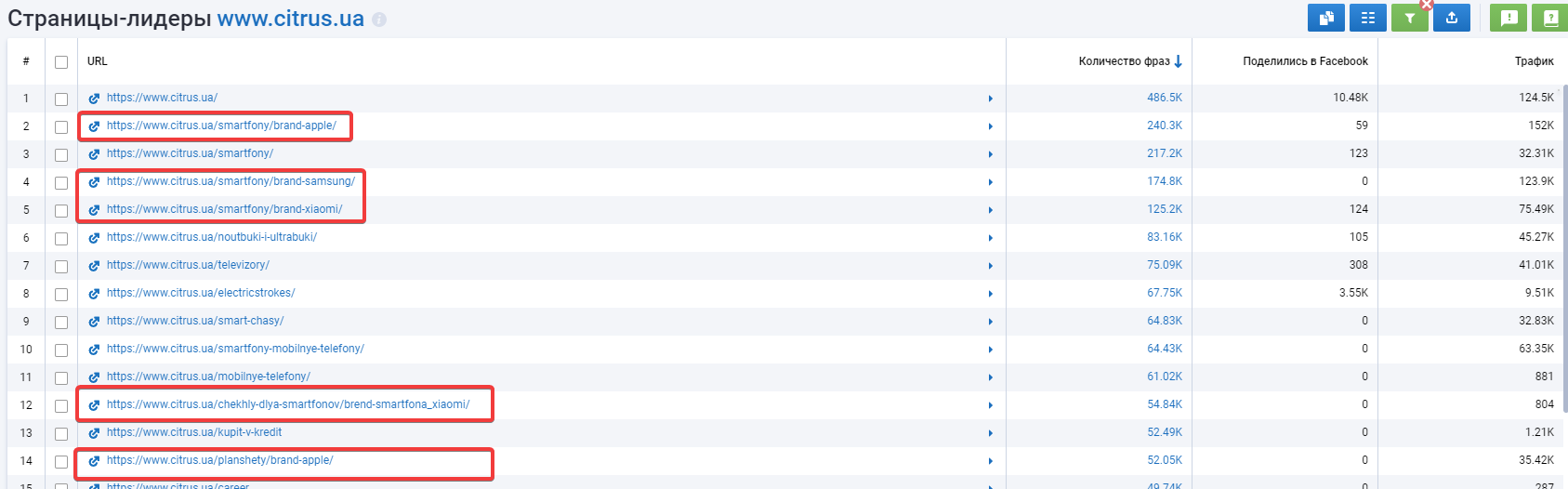
Сайт: https://www.citrus.ua/.
Оптимизированы метаданные: да.
ЧПУ URL: да.
Пример страницы фильтров: https://www.citrus.ua/smartfony/brand-apple/.
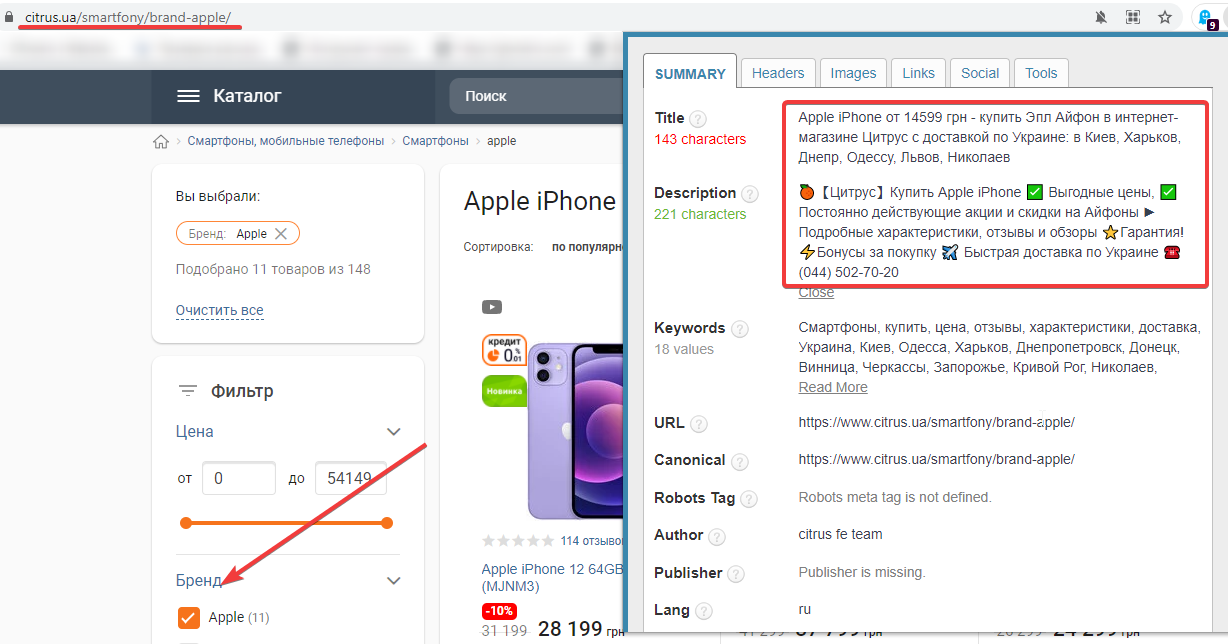
Ранжирование страниц фильтров:
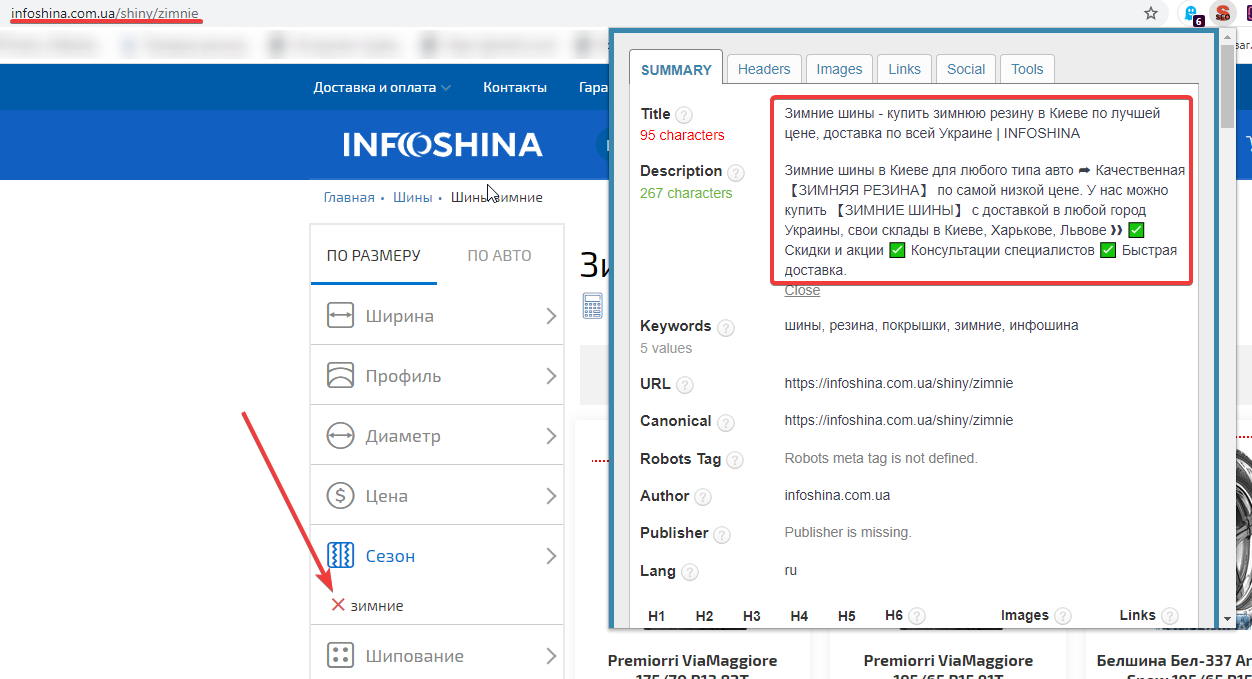
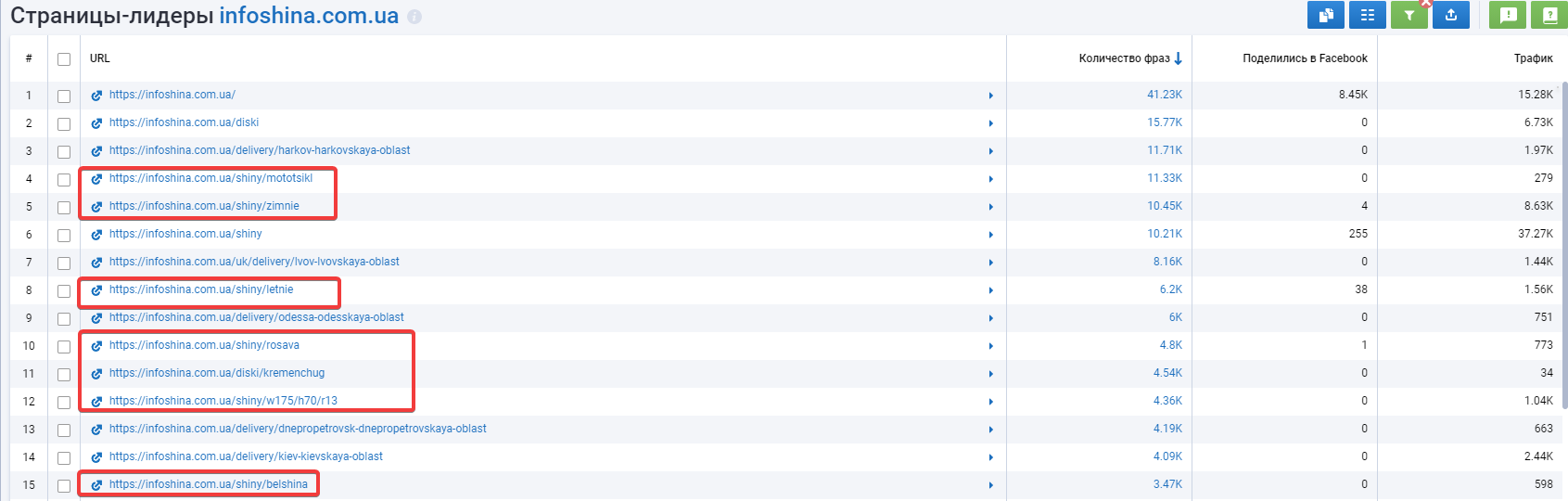
Сайт: https://infoshina.com.ua/.
Оптимизированы метаданные: да.
ЧПУ URL: да.
Пример страницы фильтров: https://infoshina.com.ua/shiny/zimnie.
Ранжирование страниц фильтров:
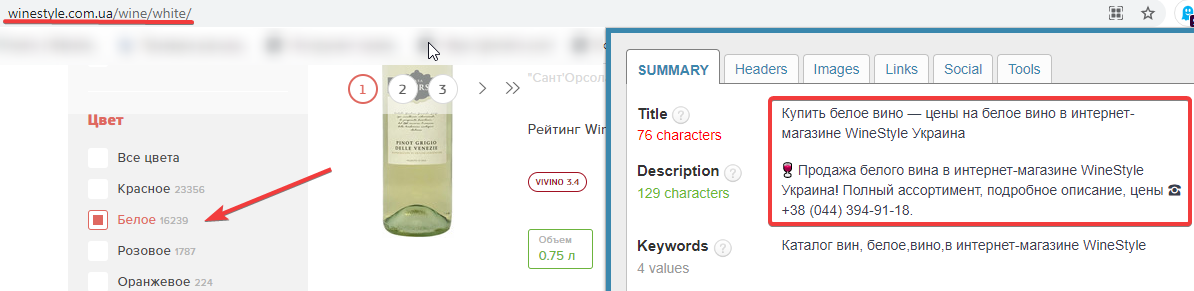
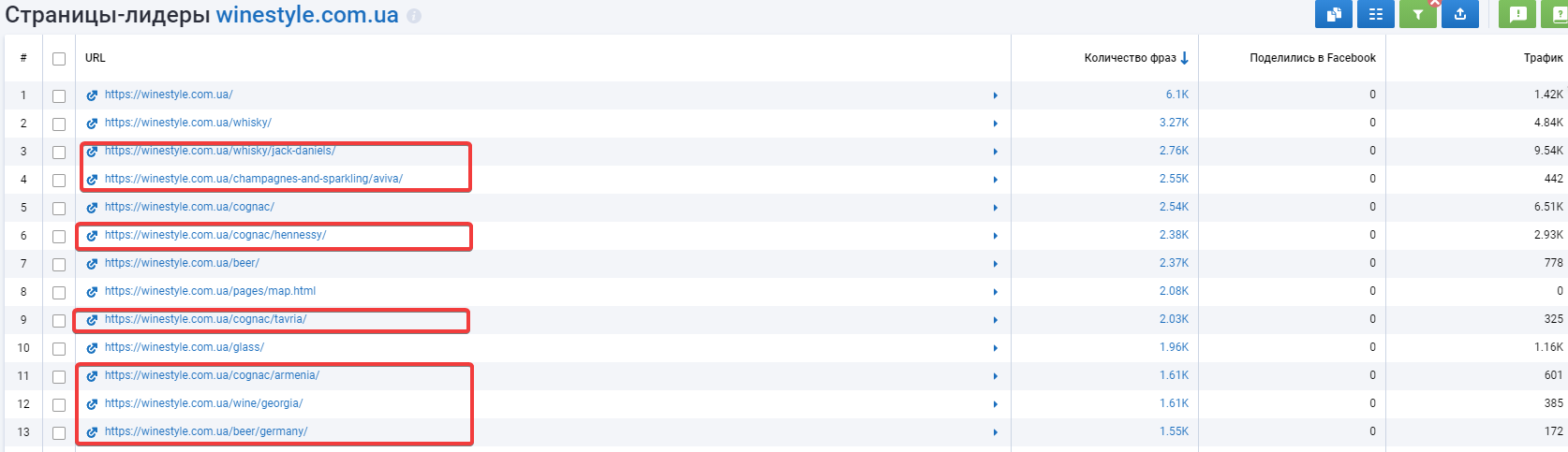
Сайт: https://winestyle.com.ua/.
Оптимизированы метаданные: да.
ЧПУ URL: да.
Пример страницы фильтров: https://winestyle.com.ua/wine/white/.
Ранжирование страниц фильтров:
Выводы
Оптимизация страниц фильтров интернет-магазина позволяет увеличить количество пользователей и онлайн-покупок. О правильной оптимизации страницы фильтрации стоит задуматься еще на этапе разработки сайта.
Создать страницы фильтров можно с помощью:
- системы Ajax;
- добавления GET-параметра;
- использования статического URL и статического ЧПУ URL.
Использование статического человекопонятного URL — самый оптимальный метод оптмизации фильтров, но нужно помнить, что его поддерживают не все CMS. Рекомендуем проверить это еще на старте работ по онлайн-магазину.
На что следует обратить внимание при оптимизации страниц фильтров:
- индексация важных и мусорных страниц;
- формирование URL-страниц;
- формирование метаданных и возможность размещения контента на сайте;
- перелинковка страниц фильтров.